
7 Quels sont les composants d’un robot? Capteurs, actionneurs et algorithmes
Jiefei Wang and Damith Herath
Table des matières
Une perspective de l’industrie : Entrevue avec Vitaliy Khomko, développeur d’applications de vision Kinova Inc.
7.3 Détecter : Détecter le monde à travers de capteurs
7.3.1 Caractéristiques typiques des capteurs
7.3.1.1 Proprioceptif et extéroceptif
7.3.1.2 Capteurs passifs et actifs
7.3.1.3 Erreurs de capteur et bruit
7.3.1.4 Autres caractéristiques communes des capteurs
7.3.2 Capteurs couramment utilisés en robotique
7.3.2.2 Capteurs sonar (ultrasons)
7.3.2.6 Unités de mesure inertielle
7.3.2.8 Capteurs de force et tactiles
7.3.2.9 Autres capteurs couramment utilisés en robotique
7.5 Agir : Se déplacer à l’aide de vérins
7.5.1 Actionneurs couramment utilisés en robotique
7.5.1.2 Actionneurs hydrauliques
7.5.1.3 Actionneurs pneumatiques
7.6 Vision par ordinateur en robotique
7.6.1.2 Méthode de croissance de la région
7.6.2.1 Méthode Lucas-Kanade et méthode Horn-Schunck
7.6.2.2 Méthodes basées sur l’énergie
7.6.2.3 Méthodes basées sur la phase
7.1 Objectifs d’apprentissage
Ce chapitre explore un cadre et certains des principaux éléments constitutifs du développement de robots. Vous apprendrez à connaître :
- Le Sense, Think, La boucle Act;
- Les différents types de capteurs qui permettent aux robots de « ressentir » le monde et de trouver les capteurs adaptés à des scénarios spécifiques;
- Les algorithmes qui rendent les robots « intelligents »;
- Les actionneurs qui font bouger les robots;
- Algorithmes de vision par ordinateur couramment utilisés qui permettent aux robots de « voir ».
7.2 Introduction
Au chapitre 4, nous avons expliqué que la programmation pouvait être considérée comme une entrée, un processus et une sortie. Détecter, Penser, Agir est un paradigme similaire utilisé en robotique. Un robot pourrait être considéré rudimentairement comme un objet analogue à la façon dont un humain ou un animal réagit aux stimuli environnementaux. Par exemple, nous, les humains, percevons l’environnement à travers les cinq sens (par exemple la vue). Nous pourrions alors « décider » de l’action suivante à prendre en fonction de ces signaux entrants et, finalement, exécuter l’action à travers nos membres. Par exemple, vous pourriez repérer (reconnaître) un visage familier parmi la foule et penser qu’il serait bon d’attirer leur attention, et ensuite agir sur cette pensée en agitant la main.
De même, un robot peut avoir plusieurs capteurs à travers lesquels il peut détecter ce qui se passe autour de lui. Un algorithme pourrait alors être utilisé pour interpréter et décider d’une action basée sur les informations sensorielles entrantes. Ce processus de calcul pourrait être considéré comme analogue au processus de pensée chez les humains. Finalement, l’algorithme envoie un ensemble d’instructions aux actionneurs du robot pour mettre en exécution les actions qui s’imposent en fonction des informations reçues du capteur et des objectifs.

Figure 7-1 : La boucle « Détecter-Penser-Agir » en robotique
La configuration actuelle du robot est appelée l’état du robot. L’espace d’état du robot englobe l’ensemble des états potentiels dans lesquels un robot pourrait se trouver. Les états observables correspondent à ceux qui sont entièrement visibles pour le robot, tandis que d’autres états peuvent être cachés ou partiellement visibles pour le robot. Ces états sont appelés des états partiellement observables. Certains états sont discrets (par exemple, moteur allumé ou éteint), tandis que d’autres peuvent être continus (par exemple, vitesse de rotation du moteur). Dans le paradigme ci-dessus, l’élément « Détecter » observe l’état, et l’élément « Agir » procède à la modification de l’état.
Une perspective de l’industrie
Entrevue avec Vitaliy Khomko, développeur d’applications de vision Kinova Inc.
Ma découverte de la robotique a commencé lorsque j’ai intégré JCA Technologies au Manitoba en 2015. À l’époque, la technologie des capteurs et des contrôleurs avait atteint un haut niveau de maturité, permettant aux innovateurs de concevoir des équipements agricoles et de construction, intelligents et capables d’exécuter de nombreuses opérations complexes de manière autonome, avec une intervention minimale d’un opérateur de machine. Franchement, je n’ai pas choisi la robotique. J’ai simplement été aspiré par le tourbillon technologique parce que l’industrie avait besoin d’innovations, de chercheurs et développeurs pour la mener de l’avant. En 2018, j’ai rejoint l’équipe de passionnés de robotique de Kinova, située au Québec, en tant que développeur de technologie de vision. Pendant de nombreux mois, j’ai été stimulé par l’atmosphère créative qui émanait des employés de Kinova. J’ai travaillé dur pendant la journée en essayant de faire de mon mieux pour m’intégrer et j’ai continué à apprendre de nouvelles choses le soir pour combler mes lacunes. Tout ce travail acharné a bien payé à la fin. Je dois avouer qu’à présent, je suis capable de faire de la magie avec un robot équipé de vision.
De loin, l’apprentissage continu et la surveillance de toutes les tendances de l’industrie sont les tâches les plus difficiles et chronophages. Cependant, avoir seulement des connaissances théoriques peut aider à rester sur la bonne voie. En réalité, la livraison d’un véritable produit de consommation exige un effort considérable en termes de recherche et d’évaluation, de planification du travail, de développement/codage et de tests. Entretenir une bonne relation avec vos collègues est essentiel. En fin de compte, ce sont les membres de votre équipe qui peuvent vous aider à sortir d’une impasse, qui partagent votre passion et votre enthousiasme, qui apprécient vos efforts et vous permettent de vous sentir connecté. Il n’y a rien qui puisse réellement se comparer à la satisfaction d’un accomplissement commun, lorsque vous pouvez partager une bière avec vos collègues à la fin d’une longue journée, après avoir franchi une étape importante et regardé le robot effectuer son travail de manière répétitive et fiable.
En ce qui concerne l’évolution, j’ai constaté le passage des équipements automatisés simples, contrôlés par des experts humains, à des machines autonomes très efficaces capables de prendre des décisions. Les capteurs existent depuis longtemps. En plaçant des capteurs de manière stratégique dans une machine, il est possible d’obtenir une quantité sans précédent de rétroaction de la part de la machine, ce qui permet un meilleur contrôle et une précision de fonctionnement. Cependant, la quantité d’informations et les contraintes en temps réel peuvent être trop importantes, même pour un opérateur humain expert. De nos jours, ce qui a véritablement marqué la différence, c’est la disponibilité d’algorithmes et de dispositifs de calcul, permettant ainsi un certain degré d’autonomie à la machine. Par exemple, la technologie des caméras est désormais largement répandue. Cependant, ce n’est pas uniquement la caméra seule qui permet la robotique guidée par la vision. Des tâches telles que l’étalonnage robot-caméra, l’appariement d’objets en 2D/3D et la validation de l’autorisation de localisation ont contribué à cette évolution. Certains pourraient penser que les récents développements de l’intelligence artificielle sont principalement responsables de cette évolution. Je pense que l’IA n’est qu’un outil parmi d’autres. Et en aucun cas la solution ultime à tous les problèmes.
7.3 Détecter : Détecter le monde à travers de capteurs
Tout change dans le monde réel. Certains changements sont notables tandis que d’autres sont subtils, certains sont induits et certains sont provoqués. Cependant, ces changements révèlent toujours des informations cachées à la perception initiale. La détection des changements dans l’environnement, revêt une importance particulière, car elle permet la perception et l’interaction avec le monde qui nous entoure. Un exemple courant est la façon dont les humains perçoivent les déplacements de motifs colorés sur leur rétine et utilisent cette information pour comprendre les changements en cours. Certains animaux, comme les chauves-souris, peuvent utiliser l’écholocation pour déterminer les changements dans leur environnement et se localiser. Contrairement aux humains ou aux animaux, les robots n’ont pas de sens naturels. En conséquence, les robots nécessitent des capteurs supplémentaires pour les aider à détecter l’environnement, ainsi que des algorithmes pour traiter et comprendre les informations recueillies par ces capteurs. Par exemple, un capteur typique tel qu’une caméra vidéo peut être considéré comme les « yeux » du robot. Un capteur sonar pourrait être considéré comme l’équivalent de l’écholocation chez une chauve-souris. En équipant les robots de différents types de capteurs intégrés, ces derniers peuvent accomplir une variété de tâches comme les êtres humains.
7.3.1 Caractéristiques typiques des capteurs
Les capteurs peuvent être caractérisés de différentes manières. Examinons d’abord certaines des caractéristiques communes et leurs définitions.
7.3.1.1 Proprioceptif et extéroceptif
Comme les humains perçoivent les maux et les douleurs internes à leur corps, les robots pourraient ressentir divers états internes du robot, tels que la vitesse de ses roues/moteurs ou le courant consommé par ses circuits d’alimentation internes. De tels capteurs sont appelés proprioceptifs. D’autre part, les capteurs qui fournissent des informations sur l’environnement externe du robot sont appelés extéroceptifs.
7.3.1.2 Capteurs passifs et actifs
Un capteur qui dispose d’un détecteur pour observer ou mesurer les propriétés physiques de l’environnement est classé comme un capteur passif. Par exemple, un capteur de lumière. En revanche, un capteur actif émet son propre signal ou énergie dans l’environnement et utilise un détecteur pour observer la réaction résultant du signal émis. Par exemple, un capteur sonar.
7.3.1.3 Erreurs de capteur et bruit
Même si un capteur est bien conçu, il est encore sensible à diverses erreurs de fabrication et à des bruits environnementaux. Cependant, certaines de ces erreurs pourraient être anticipées et comprises. De telles erreurs qui sont déterministes et reproductibles sont appelées erreurs systématiques. Les erreurs systématiques pourraient être modélisées et intégrées dans le cadre des caractéristiques du capteur. D’autres erreurs sont plus difficiles à identifier. Il s’agit par exemple d’erreurs dues à des effets environnementaux ou à d’autres processus aléatoires. De telles erreurs sont appelées erreurs aléatoires. Il est crucial de comprendre ces erreurs afin de réussir le déploiement d’un système robotique. Lorsque ces informations ne sont pas facilement disponibles pour le capteur sélectionné, vous devrez procéder à une analyse d’erreur pour isoler et quantifier les erreurs systématiques et déterminer comment capturer les erreurs aléatoires.
7.3.1.4 Autres caractéristiques communes des capteurs
Vous pouvez rencontrer les termes suivants décrivant diverses autres caractéristiques d’un capteur. Il est important de comprendre ce qu’ils signifient dans un contexte donné pour utiliser le capteur approprié pour la tâche.
Résolution – La différence minimale entre deux valeurs que le capteur peut mesurer.
Exactitude – L’incertitude d’une mesure de capteur par rapport à un étalon absolu.
Sensibilité – Le plus petit changement absolu qu’un capteur peut mesurer.
Linéarité – Si la sortie produite par un capteur dépend linéairement de l’entrée.
Précision – La reproductibilité de la mesure du capteur.
Bande passante – La vitesse à laquelle un capteur peut fournir des mesures. Habituellement exprimé en Hertz (Hz) – lectures par seconde.
Plage dynamique – En fonctionnement normal, il s’agit du rapport entre les limites des entrées inférieure et supérieure du capteur. Celle-ci est généralement exprimée en décibels (dB) :
| [latex]Plage~dynamique=10\log \log _{10}\left( \dfrac{limite~supérieure }{limite~inférieure}\right)[/latex] | (7.1) |
7.3.2 Capteurs couramment utilisés en robotique
7.3.2.1 Capteurs de lumière
Les capteurs de lumière détectent la lumière et produisent une variation de tension qui est transmise au système du robot. Les deux capteurs de lumière couramment utilisés dans le domaine de la robotique sont les cellules photoconductrices et les cellules photovoltaïques. Le changement d’intensité lumineuse incidente modifie la résistance de la cellule photoconductrice. Plus de lumière entraîne moins de résistance, et vice versa. Les cellules photovoltaïques transforment la lumière du soleil en électricité Ceci est particulièrement utile lors de la planification d’un robot solaire. Alors que la cellule photovoltaïque est considérée comme une source d’énergie, une implémentation intelligente combinée à des transistors et des condensateurs peut la convertir en capteur. D’autres capteurs de lumière, tels que les phototransistors, phototubes et les dispositifs à couplage de charge (DCC), sont également disponibles.

Figure 7-2 : Un capteur de lumière commun (photorésistance)
7.3.2.2 Capteurs sonar (ultrasons)
Les capteurs sonar (également appelés capteurs à ultrasons) utilisent l’énergie acoustique pour détecter des objets et mesurer les distances entre le capteur et les objets cibles. Les capteurs sonar sont composés de deux parties principales, un émetteur et un récepteur.
L’émetteur envoie une courte impulsion ultrasonique qui est réfléchie par la surface des objets proches, puis le récepteur reçoit le signal de retour. Le capteur mesure le temps entre l’émission et la réception du signal, à savoir le temps de vol.
Connaissant le taux de transmission d’un signal ultrasonore, la distance à la cible qui reflète le signal peut être calculée à l’aide de l’équation suivante.
| [latex]Distance=(Heure × Vitesse~du~son)/ 2[/latex] | (7.2) |
Où « 2 » signifie que le son doit faire un aller-retour.
Les capteurs sonar permettent la localisation de robots mobiles en utilisant la comparaison de modèles ou la triangulation pour calculer le changement de position entre les données capturées à deux poses différentes. (Jiménez A, Seco F, 2005) Les capteurs sonar pourraient également être utilisés pour détecter des obstacles (voir la Figure 7-3).
 |
 |
Figure 7-3 : Quatre capteurs Sonar sont intégrés dans la poitrine de ce robot NAO pour l’aider à détecter tout obstacle devant lui. Un capteur tactile est intégré dans sa tête.
L’un des défis de l’utilisation de ces capteurs est leur sensibilité aux interférences provenant d’autres capteurs sonar environnants ou de capteurs fonctionnant sur la même fréquence. De plus, ces capteurs sont fortement dépendants du matériau et de l’orientation de la surface de l’objet, car ils se basent sur la réflexion des ondes de signal (Kreczmer, 2010). De nouvelles techniques, telles que CHIRP (Compressed High-Intensity Radar Pulse), ont été développées pour améliorer les performances des capteurs sonar.
Les signaux sonar ont un modèle de faisceau 3D caractéristique. Cette caractéristique les rend plus adaptés à la détection d’obstacles dans une zone étendue lorsque la géométrie exacte n’est pas nécessaire. Cependant, pour des situations nécessitant une géométrie précise, les capteurs laser offrent une meilleure solution. Il en est de même pour les capteurs LIDAR.
7.3.2.3 Laser et LIDAR
Les capteurs laser peuvent être utilisés dans plusieurs applications liées au positionnement. Il s’agit d’une technologie de télédétection pour la mesure de la distance qui consiste à transmettre un faisceau laser vers la cible et à analyser la lumière réfléchie. Les mesures de distance basées sur le laser dépendent de techniques de temps de vol ou de déphasage. Comme le capteur sonar, une courte impulsion laser est envoyée à un système de temps de vol, et le temps est mesuré lorsque le signal retourne. Un télémètre laser à faible coût populaire en robotique est montré dans la Figure 7-4. (Voir aussi Figure 7-10).

Figure 7-4 : Le télémètre Hokuyo URG-04LX
Le système LIDAR (identification, détection et télémétrie par laser) a trouvé de nombreuses applications en robotique, notamment pour la détection d’objets, l’évitement d’obstacles, la cartographie et la capture de mouvement 3D. Le système LIDAR peut être intégré au GPS et au système de navigation par inertie (INS) pour améliorer les performances et la précision des applications de positionnement en extérieur. (Aboelmagd N, Karmat TB, Georgy J , 2013)
L’un des désavantages de l’utilisation du système LIDAR est qu’il requiert une grande capacité de calcul pour traiter les données, ce qui peut affecter les performances en temps réel des applications de robots mobiles. De plus, la détection peut être problématique lorsque le matériau de l’objet est transparent, tel que le verre, car les réflexions sur ces surfaces peuvent produire des données peu fiables et trompeuses. (Takahashi T, 2007)
7.3.2.4 Capteurs visuels
Par rapport aux capteurs de proximité mentionnés précédemment, les caméras optiques sont des capteurs peu coûteux qui fournissent une quantité considérable d’informations significatives.
Les images capturées par une caméra peuvent fournir des informations riches sur l’environnement du robot une fois traitées avec des algorithmes de traitement d’image appropriés. Ces informations peuvent inclure entre autres, la localisation, l’odométrie visuelle, la détection et l’identification d’objets. Différents types de caméras, telles que les caméras stéréo, monoculaires, omnidirectionnelles, fisheye, etc., sont disponibles pour toutes sortes d’applications robotiques.
Les caméras monoculaires (Figure 7-5) sont particulièrement appropriées pour les applications où la compacité et le poids minimal sont des éléments très importants.. De plus, leur faible coût et leur déploiement facile sont les principales motivations pour leur utilisation dans les robots mobiles. Cependant, les caméras monoculaires ne peuvent fournir que des informations visuelles et ne permettent pas d’obtenir d’informations en profondeur. D’autre part, une caméra stéréo se compose d’une paire de caméras monoculaires identiques montées sur une plate-forme. Elle fournit tout ce qu’une seule caméra peut offrir ainsi que des informations supplémentaires utiles à partir de deux vues. En se basant sur le principe de parallaxe, une caméra stéréo peut estimer la carte de profondeur (une image 2D qui représente la relation de profondeur entre les objets de la scène et le point de vue de la caméra) en utilisant les deux vues de la même scène légèrement décalées. Les caméras Fisheye sont une version des caméras monoculaires qui ont un champ de vision très large et sont utiles pour éviter les obstacles dans des environnements complexes, tels que des espaces restreints et encombrés.

Figure 7-5 : Une caméra monoculaire populaire.
7.3.2.5 Capteurs RVB-D
Les capteurs RVB-D sont des capteurs visuels non conventionnels qui peuvent obtenir simultanément une image visible (image RVB) et une carte de profondeur de la même scène. Ils sont largement utilisés dans la communauté robotique pour le traitement d’images en temps réel, la localisation du robot et l’évitement d’obstacles. Cependant, leur portée limitée et leur sensibilité au bruit les rendent principalement adaptés aux environnements intérieurs.
Le capteur Kinect, introduit sur le marché en novembre 2010, est l’un des capteurs RGB-D les plus connus. (Oui! C’est le même capteur que celui utilisé pour les jeux vidéo sur Xbox. Depuis lors, il est devenu très populaire. La communauté de la vision par ordinateur a rapidement réalisé que cette technologie de détection de profondeur pouvait être utilisée à d’autres fins, tout en étant moins coûteuse que certaines caméras tridimensionnelles (3D) traditionnelles, telles que celles basées sur le temps de vol. En juin 2011, Microsoft a publié un SDK pour le Kinect, destiné à être utilisé comme outil pour les produits non commerciaux.

Figure 7-6 : Une version plus récente du capteur Microsoft® Kinect.
Le principe de base du capteur de profondeur Kinect est l’émission d’un motif de tacheture IR (invisible à l’œil nu) et la capture simultanée d’une image IR par une caméra CMOS équipée d’un filtre IR. Le Kinect utilise un algorithme de traitement d’image qui utilise les positions relatives des points dans un modèle de tacheture (voir Figure 7-7)pour calculer le déplacement en profondeur à chaque position de pixel dans l’image, ce qu’on appelle la technique de la lumière structurée. Par conséquent, le capteur de profondeur peut fournir les coordonnées x, y et z de la surface des objets 3D.
Le capteur Kinect se compose d’un émetteur laser IR et de caméras IR et RVB. Il capture simultanément des images en profondeur et en couleur à des fréquences d’images allant jusqu’à 30 Hz. La caméra couleur RVB fournit des images à 640 × 480 pixels et 24 bits à la fréquence d’images la plus élevée. En revanche, la caméra IR de 640 × 480 et 11 bits par pixel offre 2048 niveaux de sensibilité avec un champ de vision de 50 degrés horizontal et 45 degrés vertical. La plage de fonctionnement du capteur Kinect est de 50 cm à 400 cm.

Figure 7-7 : Une vue d’une caméra RVB-D (de gauche à droite – image RVB, image de profondeur, image IR montrant le motif projeté).
7.3.2.6 Unités de mesure inertielle
Une unité de mesure inertielle (UMI) utilise des gyroscopes et des accéléromètres (et éventuellement des magnétomètres et des baromètres) pour détecter le mouvement et l’orientation. Un accéléromètre est un dispositif qui sert à mesurer l’accélération et l’inclinaison. Deux types de forces affectent un accéléromètre : la gravité qui aide à déterminer l’inclinaison du robot. Cette mesure permet d’équilibrer le robot ou de déterminer si un robot roule sur une surface plane ou en montée – l’autre force est la force dynamique qui correspond à l’accélération nécessaire pour déplacer un objet. Ces capteurs sont utiles pour déduire des changements incrémentiels de mouvement et d’orientation. Cependant, ils souffrent de biais, de dérive et de bruit. Cela nécessite un étalonnage régulier du système avant utilisation ou des techniques sophistiquées de fusion de capteurs et de filtrage (tel que filtre de Kalman élargi décrit au Chapitre 9). Vous verrez souvent des UMI utilisées avec des systèmes de vision par ordinateur ou combinées avec des informations GNSS (Global Navigation Satellite System). De tels systèmes sont communément appelés systèmes INS/GNSS (Intertial Navigation Systems/GNSS).
7.3.2.7 Encodeurs
Tout simplement, les encodeurs enregistrent les mesures de mouvement sous une forme ou une autre. Il existe trois types d’encodeurs : les encodeurs linéaires, les encodeurs rotatifs et les encodeurs angulaires.
Les encodeurs linéaires mesurent le mouvement en ligne droite. Les têtes de capteur qui se fixent à la pièce mobile de la machinerie sont installées le long des rails de guidage. Ces capteurs sont reliés à une échelle à l’intérieur de l’encodeur qui envoie des signaux numériques ou analogiques au système de contrôle. Les encodeurs rotatifs mesurent le mouvement de rotation. Ils entourent généralement un arbre en rotation, détectant et communiquant les changements de son mouvement angulaire. Traditionnellement, les encodeurs rotatifs sont classés comme ayant des précisions supérieures à ± 10″ (secondes d’arc). Des encodeurs rotatifs sont également disponibles, avec d’importantes capacités de sécurité fonctionnelle. Semblables à leurs homologues rotatifs, les encodeurs angulaires mesurent la rotation. Ceux-ci, cependant, sont le plus souvent utilisés dans les applications où une mesure précise est requise.
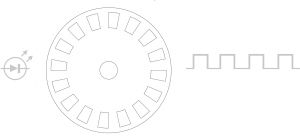
Figure 7-8 : un encodeur incrémental rotatif simplifié à 16 fentes
Les robots mobiles utilisent souvent des encodeurs pour calculer leur odométrie. L’odométrie est l’utilisation de capteurs de mouvement pour déterminer le changement temporel de position du robot par rapport à une position connue. Un exemple simple d’utilisation d’un encodeur incrémental rotatif pour calculer la distance de déplacement du robot pourrait être illustré comme suitFigure 8. Une lumière est projetée à travers un disque fendu (généralement en métal ou en verre). Lorsque le disque tourne, la lumière qui traverse les fentes est captée par un capteur de lumière placé à l’autre côté du disque. Ce signal pourrait être converti en une onde sinusoïdale ou carrée à l’aide de circuits électroniques. En attachant cet encodeur à l’axe de la roue du robot, nous pourrions utiliser le signal de sortie pour calculer la vitesse à laquelle le robot se déplace et ainsi mesurer la distance de déplacement.
Pour calculer la longueur parcourue L (cm) en utilisant la sortie d’un encodeur incrémental, on commence par calculer le nombre d’impulsions par cm (PPCM) :
| [latex]PPCM=\dfrac{PPR}{2\pi r}[/latex] | (7.3) |
Où PPR est le nombre d’impulsions par tour – ce qui, dans l’exemple Figure 7-8 est 16,
alors la longueur L est donnée par :
| [latex]L=\dfrac{Impulsions}{PPCM}[/latex] | (7.4) |
La vitesse (S) est alors calculée comme suit :
| [latex]S=\dfrac{L}{Durée}[/latex] | (7.5) |
II convient de souligner que la proximité requise de ces capteurs avec les moteurs les expose souvent à des interférences électromagnétiques. Par conséquent, pour améliorer la précision de l’encodeur et déterminer le sens de rotation, un deuxième ensemble de lumière-capteur est inclus avec un déphasage de 90°. (Figure 7-9)

Figure 7-9 : Un encodeur incrémental rotatif de loisir populaire avec deux sorties (encodeur en quadrature)
7.3.2.8 Capteurs de force et tactiles
Ces deux types de capteurs mesurent les interactions physiques entre le robot et l’environnement extérieur. Un capteur de force typique est généralement utilisé pour mesurer une force mécanique externe, par exemple sous la forme d’une charge, d’une pression ou d’une tension. Les capteurs tels que les jauges de contrainte et les manomètres font partie de cette catégorie. D’autre part, les capteurs tactiles sont généralement utilisés pour imiter le sens du toucher. Généralement, les capteurs tactiles sont censés mesurer de petites variations de force ou de pression avec une sensibilité élevée. Les robots conçus pour être interactifs intègrent de nombreux capteurs tactiles afin qu’ils puissent répondre au toucher (par exemple Figure 7-3). De plus en plus, des capteurs sophistiqués émergent pour imiter la sensibilité au toucher de la peau. Une version plus simple de cette technologie est présente sur la plupart des robots aspirateurs, où le pare-chocs avant sert de détecteur de collisions.(Figure 7-10).

Figure 7- 10 : Un robot aspirateur moderne intègre de nombreux capteurs. Sur le dessus se trouve un scanneur laser à temps de vol. Le pare-chocs avant comprend plusieurs capteurs tactiles pour détecter d’éventuelles collisions frontales. Selon vous, quels autres capteurs ce robot pourrait-il avoir?
7.3.2.9 Autres capteurs couramment utilisés en robotique
De nombreux autres capteurs sont utilisés en robotique, et de nouveaux sont développés dans divers laboratoires de recherche et commercialisés régulièrement. Ceux-ci incluent des microphones (signaux auditifs), des boussoles, des capteurs de température (capteurs thermiques et infrarouges), des capteurs chimiques et bien d’autres. Par conséquent, il est prudent de rechercher des capteurs appropriés pour votre prochain projet, car de nouveaux capteurs plus performants peuvent mieux répondre à vos besoins. Pouvez-vous penser à tous les capteurs qui peuvent être utilisés dans le robot illustré dans la Figure 7-10 ?
7.4 Penser : Algorithmes
La capacité d’un système robotique à traiter les informations sensorielles disponibles et à accomplir les tâches et les objectifs qui lui sont assignés est un élément essentiel de son fonctionnement. Si les cerveaux d’un robot sont les ordinateurs intégrés dans le système robotique, les algorithmes sont les composants logiciels qui permettent à un robot de « penser » et de prendre des décisions. Les informations sensorielles disponibles sont interprétées par les algorithmes qui prennent des décisions de contrôle et effectuent les tâches assignées en fonction de l’environnement.
De manière générale, un algorithme est une liste finie d’instructions permettant de résoudre des problèmes ou de réaliser des tâches. Pour mieux comprendre le concept d’algorithmes, prenons l’exemple de la réalisation d’une génoise. Comment pourriez-vous écrire toutes les étapes de manière détaillée et ordonnée pour qu’une personne qui ne sait pas cuisiner puisse faire une génoise? Répondre à ces questions de manière détaillée et ordonnée constitue un algorithme. Une des caractéristiques principales d’un algorithme est qu’il suit un processus systématique et précis dans un ordre spécifique. Le mauvais ordre des étapes peut entraîner une grande différence. Par exemple, si l’on change l’ordre des étapes de préparation d’une génoise, comme mettre les œufs et la farine au four pendant une demi-heure avant de préchauffer le four. Cela n’aurait aucun sens !
Pour un système robotique, les algorithmes sont comme des recettes spécifiques qui les aident à « penser ». Ce sont des séquences précises d’instructions qui sont implémentées à l’aide de langages de programmation. Les éléments essentiels d’un algorithme comprennent l’entrée, la séquence, la sélection, l’itération et la sortie.
- L’entrée correspond aux données, aux informations ou aux signaux collectés par les capteurs ou une commande d’un opérateur humain. La séquence concerne l’ordre dans lequel les comportements et les commandes sont combinés pour produire le résultat souhaité.
- Sélection – est l’utilisation d’instructions conditionnelles dans un processus. Par exemple, le processus peut être influencé par des instructions conditionnelles telles que [If then] ou [If then else].
- Itération – Les algorithmes peuvent également utiliser la répétition pour exécuter des étapes plusieurs fois ou jusqu’à ce qu’une condition spécifique soit atteinte. Cela est également connu sous le nom de « boucle ».
- Sortie – Le résultat souhaité ou attendu, tel que le robot atteignant la destination cible ou évitant la collision avec des obstacles.
La robotique est remplie d’algorithmes de toutes sortes, allant du simple évitement d’obstacles à la compréhension de scènes complexes à l’aide de plusieurs capteurs. . Parmi eux, les algorithmes de vision par ordinateur jouent un rôle crucial dans la capacité des robots à interpréter les riches informations générées par les différents systèmes de caméras optiques mentionnés précédemment. Par conséquent, nous aborderons certains des algorithmes de vision couramment utilisés en robotique.
7.5 Agir : Se déplacer à l’aide de vérins
Nous identifions les robots comme des objets qui se déplacent ou qui sont dotés de pièces mobiles. Dans le paradigme « Détecter, Penser, Agir », Agir fait référence à cet aspect dynamique des robots. Le robot agit sur l’environnement en le manipulant à l’aide de divers appendices appelés manipulateurs (robots à bras) ou en le traversant (robots mobiles). Pour agir, un robot a besoin d’actionneurs. Un actionneur est un dispositif qui convertit l’énergie, telle qu’un signal électrique, hydraulique, pneumatique ou externe, en un mouvement contrôlable.
7.5.1 Actionneurs couramment utilisés en robotique
7.5.1.1 Moteurs
Le moteur électrique est un exemple typique d’actionneur entraîné électriquement. Comme ils peuvent être fabriqués dans différentes tailles, types et capacités, ils conviennent à une large gamme d’applications robotiques. Il existe différents moteurs électriques, tels que les servomoteurs, les moteurs pas-à-pas et les moteurs linéaires.
Servomoteurs
Un servomoteur est un dispositif qui permet de contrôler la position, la vitesse et le couple d’un mouvement à l’aide d’un signal électrique, analogique ou numérique. Il permet de contrôler la position, la vitesse et le couple. Les servomoteurs sont classés en différents types en fonction de leur utilisation, notamment les servomoteurs AC et DC.
La vitesse d’un moteur à courant continu est proportionnelle à la tension d’alimentation à charge constante, tandis que pour un moteur à courant alternatif, la vitesse est déterminée par la fréquence de la tension appliquée et le nombre de pôles magnétiques. Les moteurs à courant alternatif sont couramment utilisés dans les applications d’asservissement en robotique et dans la fabrication en ligne et d’autres applications industrielles où des répétitions élevées et une haute précision sont requises.
Les servomoteurs à courant continu peuvent être commutés soit mécaniquement avec des balais, soit électroniquement sans balais. Les moteurs à balais sont généralement moins coûteux et plus faciles à utiliser, tandis que les moteurs sans balais sont plus fiables, ont un rendement plus élevé et sont moins bruyant
 |
 |
Figure 7-11 : Servomoteurs DC Hobby (à gauche) et un actionneur haut de gamme (à droite) utilisés dans un bras de robot industriel (avec l’aimable autorisation de Kinova Robotics)
Moteurs pas-à-pas
Un moteur pas-à-pas est un moteur à courant continu synchrone sans balais, qui présente des mouvements angulaires discrets et précis. Un moteur pas à pas est conçu pour décomposer une seule rotation complète en un certain nombre de rotations partielles beaucoup plus petites et essentiellement égales. À des fins pratiques, ceux-ci peuvent être utilisés pour demander au moteur pas à pas de se déplacer à travers des degrés ou des angles de rotation définis. Le résultat final est qu’un moteur pas à pas permet de transmettre des mouvements précis à des pièces mécaniques qui exigent un haut degré de précision. Les moteurs pas à pas sont très polyvalents, fiables, économiques et fournissent des mouvements de moteur précis, permettant aux utilisateurs d’accroître la dextérité et l’efficacité des mouvements programmés dans une grande variété d’applications et d’industries. La plupart des imprimantes 3D, par exemple, utilisent plusieurs moteurs pas à pas pour contrôler avec précision la tête d’impression 3D.
Moteurs linéaires
Un moteur linéaire opère sur le même principe qu’un moteur électrique, mais fournit un mouvement linéaire plutôt que rotatif. Contrairement à un moteur rotatif, un moteur linéaire déplace un objet en ligne droite ou le long d’une trajectoire courbe. Les moteurs linéaires peuvent atteindre des accélérations très élevées allant jusqu’à 6 g et des vitesses de déplacement pouvant atteindre 13 m/s. Cette caractéristique les rend particulièrement adaptés aux machines-outils, aux systèmes de positionnement et de manutention, ainsi qu’aux centres d’usinage.
7.5.1.2 Actionneurs hydrauliques
Les actionneurs hydrauliques sont entraînés par la pression du fluide hydraulique. L’ensemble de l’actionneur est composé d’un cylindre, d’un piston, d’un ressort, d’une conduite d’alimentation et de retour hydraulique ainsi que d’une tige. Ils peuvent produire de grandes quantités d’énergie. C’est pourquoi les actionneurs hydrauliques sont utilisés dans les machines de construction et autres équipements lourds.
Les actionneurs hydrauliques présentent certains avantages. Un actionneur hydraulique peut maintenir la force et le couple constants sans que la pompe fournisse plus de fluide ou de pression en raison de l’incompressibilité des fluides. Les actionneurs hydrauliques peuvent avoir leurs pompes et leurs moteurs situés à une distance considérable avec une perte de puissance minimale. En comparant les vérins pneumatiques de même taille, les forces générées par les actionneurs hydrauliques sont 25 fois plus importantes, ce qui garantit leur bon fonctionnement dans des environnements difficiles. Cependant, l’un des inconvénients de l’utilisation d’actionneurs hydrauliques est qu’ils peuvent fuir, ce qui entraîne une efficacité réduite et, dans des cas extrêmes, des dommages aux équipements à proximité en raison d’un déversement. Les actionneurs hydrauliques nécessitent de nombreuses pièces complémentaires, notamment un réservoir de fluide, un moteur, une pompe, des soupapes de décharge, des échangeurs de chaleur ainsi qu’un équipement de réduction du bruit.
7.5.1.3 Actionneurs pneumatiques
Les actionneurs pneumatiques sont reconnus pour leur fiabilité, leur efficacité et leur sécurité en matière de contrôle de mouvement. Ils sont entraînés par de l’air sous pression qui peut convertir l’énergie de l’air comprimé en mouvement mécanique linéaire ou rotatif. Les actionneurs pneumatiques sont couramment utilisés dans les moteurs à combustion interne, les applications ferroviaires et l’aviation. Ils sont largement utilisés dans les moteurs automobiles combustibles, les applications ferroviaires et l’aviation. Les avantages de l’utilisation d’actionneurs pneumatiques plutôt que d’actionneurs alternatifs, tels que les actionneurs électriques, sont principalement la fiabilité des dispositifs et les aspects de sécurité. Les actionneurs pneumatiques sont également très durables, nécessitant peu d’entretien et offrant de longs cycles de fonctionnement.
7.5.1.4 Actionneurs modernes
De nombreux nouveaux procédés d’actionnement et d’actionneurs ont été développés ces derniers temps. Il s’agit notamment des tendons pneumatiques (Figure 7-12) et d’autres actionneurs d’inspiration biologique, tels que les nageoires de poisson ou les tentacules de poulpe. La robotique douce est un domaine émergent qui explore certains des développements récents en matière de robotique. Cependant, les exigences de conformité et la morphologie des robots mous rendent difficile l’utilisation de nombreux capteurs conventionnels qui sont couramment utilisés dans les robots durs. Pour répondre à ce défi, des recherches actives ont été menées sur les capteurs électroniques extensibles. Les capteurs en élastomère permettent une faible influence sur l’actionnement du robot.

Figure 7-12 : Par exemple, les muscles pneumatiques en caoutchouc ont été utilisés pour animer une structure robotique géante lors d’une performance de l’artiste Stelarc (Reclining StickMan, Biennale d’art australien d’Adélaïde 2020 : Photographeur Monster Theatres – Saul Steed, Stelarc)
7.6 Vision par ordinateur en robotique
Depuis des décennies, les techniques de vision par ordinateur suscitent un intérêt croissant et des recherches rigoureuses afin de permettre une appréhension plus précise et complexe du monde qui nous entoure. En effet, la vision par ordinateur vise à atteindre une compréhension de la scène et des objets qui la composent. De plus, la puissance de calcul croissante et les progrès des méthodes de vision par ordinateur ont rendu la conception de robots qui peuvent « voir », une tendance populaire. Comme la vision par ordinateur combine à la fois des capteurs et des algorithmes, elle mérite sa propre section unique dans ce chapitre.
La vision par ordinateur en robotique fait référence à la capacité d’un robot à percevoir visuellement et à interagir avec l’environnement. Les tâches typiques consistent à reconnaître des objets, à détecter les plans du sol, à traverser un emplacement cible donné sans entrer en collision avec des obstacles, à interagir avec des objets dynamiques et à répondre aux intentions humaines.
La vision est utilisée dans diverses applications robotiques depuis plus de trois décennies. La vision par ordinateur est utilisée depuis plus de trois décennies dans diverses applications robotiques, notamment dans les environnements industriels, de service, médicaux et sous-marins, pour n’en citer que quelques-unes. La section qui suit exposera des algorithmes classiques de vision par ordinateur largement utilisés en robotique, notamment la détection du plan, le flux optique et l’odométrie visuelle.
7.6.1 Détection du plan
La détection du plan est une tâche cruciale pour les systèmes de robot mobile autonome, car elle permet l’évitement d’obstacles et la planification de la trajectoire. Le plan dominant est défini comme une surface plane occupant la plus grande région au sol vers laquelle le robot se dirige. Il fournit des informations utiles sur l’environnement, en particulier sur la présence d’obstacles au-dessus de la surface dominante plane détectée et le long de la direction du mouvement du robot. Pour mener à bien leur mission dans un environnement inconnu, les robots mobiles terrestres et les micro-véhicules aériens doivent d’abord identifier le milieu environnant. Ils doivent être capables de détecter les obstacles dans leur zone de fonctionnement et de les éviter ou de les traverser si possible. Différentes techniques de détection du plan existent, telles que RANSAC et la méthode de croissance de région.
7.6.1.1 RANSAC
Le consensus de l’échantillon aléatoire (RANSAC) (Fischler et Bolles, 1981) est une méthode itérative pour estimer les paramètres d’un modèle mathématique à partir d’un ensemble de données observées contenant des valeurs aberrantes. Cet algorithme est un outil très utile pour la détection de plans à partir de nuages de points tridimensionnels (3D). Il est efficace en termes de calcul même lorsque le nombre de points est important. Le principe de la détection de plan à l’aide de RANSAC consiste en la sélection aléatoire de trois points dans le nuage de points, suivie du calcul des paramètres du plan correspondant. L’étape suivante consiste à détecter tous les points du nuage d’origine appartenant au plan calculé en fonction du seuil donné. Cette procédure est répétée N fois, en comparant à chaque fois le résultat obtenu avec le dernier résultat enregistré. Si le nouveau résultat est meilleur, il remplace le dernier enregistré (voir Algorithme 1).
Pour utiliser cet algorithme, quatre types de données sont nécessaires en entrée :
- un nuage de points 3D qui est une matrice des trois colonnes de coordonnées X, Y et Z;
- un seuil de tolérance de distance t entre le plan choisi et d’autres points;
- une probabilité (α) qui est typiquement comprise entre 0,9 et 0,99 et qui est la probabilité minimale de trouver au moins un bon ensemble d’observations en N tours;
- et le nombre maximum probable de points appartenant au même plan.
// Algorithme 1 : RANSAC pour adaptation au plan
Entrée : Données de points 3D;
Pour tous les [latex]N_{tours}[/latex] FAIRE
Sélectionnez trois points au hasard ([latex]P_{1}[/latex],[latex]P_{2}[/latex],[latex]P_{3}[/latex]) à partir des données d’entrée;
Adapter un plan à travers les points;
Configurer : [latex]N_{insertions}[/latex]=0;
Pour tous les points faire
Si la distance du point au plan est inférieure à un seuil, alors;
Incrément [latex]N_{insertions}[/latex];
Si [latex]N_{insertions}[/latex] est plus grand que le meilleur plan alors ;
Mettre à jour l’estimation du plan en utilisant tous les points;
Mettre à jour le meilleur plan;
Fin
Fin
Sortie : Plan dominant;
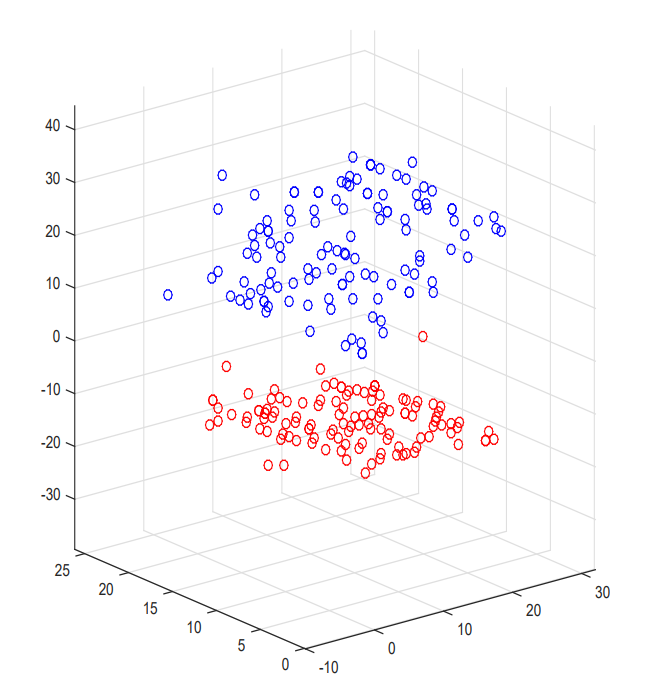
En tant que l’une des méthodes les plus connues pour la détection de plan, RANSAC s’est avéré capable de détecter des plans en 2D et en 3D. Par exemple, dans la Figure 7-13, deux groupes de points 3D bruyants (bleu et rouge) avec deux plans détectés avec succès par la méthode RANSAC.
 |
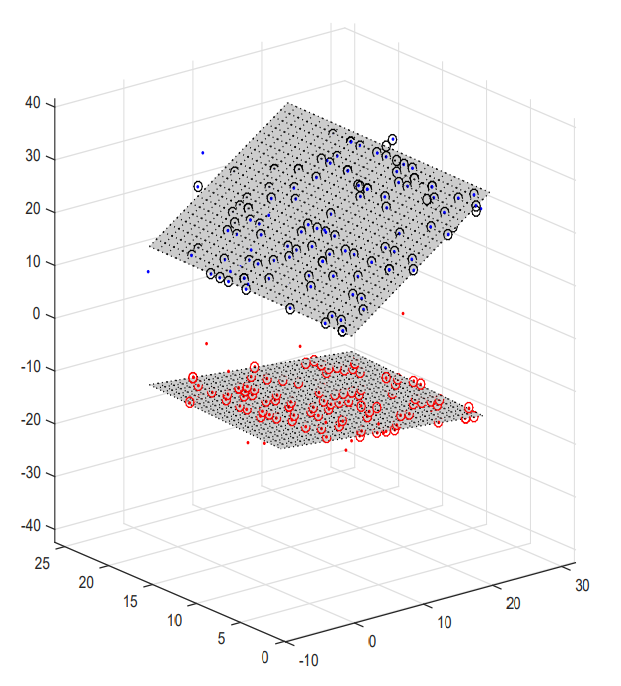 |
Figure 7-13 : Deux groupes de points 3D représentant deux plans détectés par la méthode RANSAC.
7.6.1.2 Méthode de croissance de la région
La méthode de croissance de région pour la détection de plan a été introduite pour la première fois par (Hähnel et al., 2003) dans le but de créer un modèle de faible complexité pouvant être implémenté en temps réel. Elle fonctionne à partir d’un point choisi au hasard dans le nuage de points, qui contient suffisamment d’informations pour s’adapter à un plan et ajoute plus de points en fonction de conditions de sélection spécifiques, par exemple si trois points sont nécessaires ou si un point avec une normale correspondante peut être utilisé. Ensuite, lorsque les points voisins sont cohérents avec le plan, ils sont considérés comme faisant partie de celui-ci. Cette procédure est répétée jusqu’à ce qu’il n’y ait plus de points à trouver, puis l’algorithme s’arrête et ajoute le plan s’il contient suffisamment de points. Enfin, les points sont supprimés de l’ensemble de points et un nouveau point est sélectionné. Un bref aperçu de cet algorithme est présenté dans Algorithme 2.
// Algorithme 2 : Méthode de croissance de région pour l’adaptation du plan Données de points 3D;
Pour tout point FAIRE
S= deux points voisins aléatoires [latex]P_{1}[/latex], [latex]P_{2}[/latex];
Sélectionnez le point le plus proche [latex]P_{n}[/latex]dans une certaine distance;
Si le nouveau point ajouté [latex]P_{n}[/latex] ne change pas l’estimation du plan, alors ajoutez ce point [latex]P_{n}[/latex] dans le jeu de dates sélectionné S;
Si la taille de S > certain seuil;
L’estimation du plan ajouté à un ensemble de plans;
Fin
Sortie : Ensemble de plans;
7.6.2 Flux optique
Le flux optique correspond au modèle de mouvement visible des objets, des surfaces et des bords dans une scène visuelle, qui est engendré par le déplacement relatif entre l’observateur et la scène. On pense que les insectes et les oiseaux utilisent fréquemment le flux optique pour la navigation à courte distance et l’évitement d’obstacles. Par exemple, les biologistes ont démontré que les oiseaux utilisent le flux optique pour esquiver les obstacles et contrôler les atterrissages. En outre, de nombreux mammifères peuvent également employer le flux optique pour percevoir les mouvements des objets. Toutes ces découvertes concernant le flux optique inspirent les chercheurs en robotique à concevoir des robots visuels aptes à naviguer de manière rapide et sécurisée dans des milieux inexplorés.
Le flux optique peut être traité comme les mouvements apparents des objets, aux modèles de luminosité ou aux points saillants perçus par les yeux ou les caméras. En se basant sur cette définition, il est possible de calculer le flux optique à partir de la différence entre deux séquences, qui est couramment exprimée sous cette forme :
[latex]\begin{equation} \begin{bmatrix} \dot{u} & \dot{v} \end{bmatrix}^T = f(u, v) \end{equation}[/latex], où l’unité est pix/sec or pix/frame.Le flux optique peut également être défini comme la projection du mouvement 3D relatif entre un observateur et une scène dans le plan d’image. En tant qu’image composée de nombreux pixels avec des coordonnées uniques, elle peut être décrite comme un vecteur bidimensionnel (2D) dans des séquences d’images. Par conséquent, le modèle de champ de mouvement peut être décrit comme suit :
| [latex]OF=\dfrac{V}{d}[/latex] | (7.6) |
Où OF est le champ de flux optique, V est le vecteur de vitesse de l’observateur et d est la distance entre l’observateur et le plan d’image avec l’unité normalement rad/sec ou deg/sec. Les deux définitions mentionnées ci-dessus sont les mêmes pour une situation idéale après une transformation de coordonnées.
Pendant une courte durée, les structures d’intensité des régions locales d’image variant dans le temps sont approximativement constantes. Sur la base de cette hypothèse, si [latex]I(x,t)[/latex] est la fonction d’intensité de l’image, nous avons :
| [latex]I(x, t)=I\left(x+\delta_{x}, y+\delta_{y}\right)[/latex] | (7.7) |
où [latex]\delta_{x}[/latex] est le déplacement de la région locale de l’image à [latex](x,t)[/latex]au moment [latex]t+\delta_{t}[/latex] . Cette équation développée en série de Taylor donne :
| [latex]I(x, t)=I(x, t)+\nabla_{I} \cdot \delta_{x}+\delta_{t} I_{t}+O^{2}[/latex] | (7.8) |
où [latex]\nabla_{I}=\left(I_{x}, I_{y}\right)[/latex] et [latex]I_{t}[/latex] sont les dérivées partielles du premier ordre de [latex]I(x,t)[/latex] et [latex]O^{2}[/latex] les termes de second ordre et d’ordre supérieur, qui sont négligeables. L’équation précédente peut être réécrite comme suit :
| [latex]\nabla_{I} \cdot V+I_{t}=0[/latex] | (7.9) |
divisé par [latex]\delta_{t}[/latex], où [latex]\nabla_{I}=\left(I_{x}, I_{y}\right)[/latex] est le gradient d’intensité spatiale, et [latex]V = (u,v)[/latex] est la vitesse de l’image. Ceci est connu sous le nom d’équation de contrainte de flux optique, qui définit une seule contrainte locale sur le mouvement de l’image.
 |
 |
Figure 7-14 : Flux optique détecté indiqué par des flèches rouges, plus la longueur de la flèche est longue, plus le mouvement du patch de pixels est rapide (translation à gauche, rotation à droite).
De nombreuses méthodes ont été proposées pour détecter le flux optique. Certaines techniques sont brièvement décrites ci-dessous.
7.6.2.1 Méthode Lucas-Kanade et méthode Horn-Schunck
La méthode Lucas-Kanade (B.Lucas et T, Kanade, 1981) et la méthode Horn-Schunck (BKP Horn et BG Schunk, 1981) sont des méthodes différentielles classiques largement utilisées pour l’estimation du flux optique. La méthode Lucas – Kanade suppose que le flux est constant dans un voisinage local du pixel considéré et résout les équations de base du flux optique pour tous les pixels de ce voisinage par le critère des moindres carrés. En combinant les informations de plusieurs pixels proches, la méthode Lucas-Kanade peut souvent résoudre l’ambiguïté inhérente à l’équation du flux optique. Elle est également moins sensible au bruit de l’image par rapport aux autres méthodes.
La méthode de Horn-Schunck est un autre algorithme classique d’estimation de flux optique. Il suppose une fluidité du flux sur toute l’image (globale). Ainsi, il essaie de minimiser les distorsions de flux et préfère les solutions qui montrent plus de fluidité. De ce fait, elle est plus sensible au bruit que la méthode de Lucas et Kanade. De nombreux algorithmes de flux optiques actuels sont construits sur ces modèles.
7.6.2.2 Méthodes basées sur l’énergie
Les méthodes de calcul du flux optique basé sur l’énergie sont également appelées méthodes basées sur la fréquence, car elles utilisent la sortie d’énergie des filtres accordés en vitesse. Dans certaines situations, ces méthodes peuvent être considérées comme équivalentes aux méthodes différentielles mentionnées précédemment sur le plan mathématique. Cependant, la détection de motifs de points mobiles clairsemés est plus complexe pour les méthodes différentielles et de corrélation que pour les méthodes basées sur l’énergie.
7.6.2.3 Méthodes basées sur la phase
Une technique basée sur la phase est une méthode classique pour calculer le flux optique en utilisant les comportements de phase des sorties de filtres passe-bande Cette méthode, introduite pour la première fois par Fleet et Jepson en 1990, s’est révélée plus précise que d’autres méthodes locales. La raison principale est que les informations de phase sont robustes aux changements, contrairement à l’orientation et à la vitesse de l’échelle. Cependant, ces techniques ont l’inconvénient majeur d’avoir une charge de calcul élevée associée à leurs opérations de filtrage.
Méthodes de corrélation
Les méthodes basées sur la corrélation trouvent des patchs d’image correspondants en maximisant une mesure de similarité entre eux sous l’hypothèse que les patchs d’image n’ont pas été trop déformés sur une région locale. De telles méthodes peuvent être utilisées dans des conditions de bruit élevé et de faible support temporel où les méthodes de différenciation numérique ne sont pas aussi pratiques. Elles sont couramment utilisées pour trouver des correspondances stéréo pour la tâche de récupération de profondeur.
7.6.3 Odométrie visuelle
L’odométrie visuelle est une méthode d’estimation de la position et de l’orientation de robots mobiles, tels qu’un robot terrestre ou une plate-forme volante, en utilisant l’entrée d’une ou plusieurs caméras qui y sont attachées (Scaramuzza et Fraundorfer, 2011). Elle estime une position en intégrant les déplacements obtenus à partir d’images consécutives observées à partir de systèmes de vision embarqués. Cette méthode est essentielle dans des environnements où le GPS n’est pas disponible pour un positionnement absolu (Weiss et al., 2011).
De nombreuses techniques conventionnelles d’odométrie peuvent engendrer des erreurs imprévisibles dans les mesures fournies par les gyroscopes, les accéléromètres et les encodeurs à roue. Il a été constaté que, pour les rovers d’exploration de Mars subissant de petites translations sur le sol sablonneux, de gros rochers ou des pentes abruptes, l’odométrie visuelle doit être corrigée pour les erreurs résultant des mouvements et du patinage des roues (Maimone et al., 2007). La position d’un véhicule peut être estimée à l’aide de caméras stéréo ou monoculaires, qui utilisent des techniques d’appariement ou de suivi des caractéristiques Dans (Garratt et Chahl, 2008), la translation et la rotation sont évaluées à l’aide de l’algorithme d’interpolation d’image avec une caméra orientée vers le bas. D’autres méthodes ont également été suggérées pour calculer le mouvement directement à partir des intensités d’image (Hanna, 1991) (Heeger et Jepson, 1992). Le principal inconvénient de l’utilisation d’une seule caméra est que seule la direction du mouvement peut être déterminée, et non l’échelle de vitesse absolue, ce qui est appelé le problème du facteur d’échelle. Cependant, l’utilisation d’une caméra omnidirectionnelle peut résoudre ce problème; par exemple, la navigation sécurisée dans un couloir pour un MAV (Micro Air Vehicle) utilisant une méthode de flux optique est réalisée dans (Conroy et al., 2009), mais cette opération nécessite beaucoup de temps de calcul.
7.7 Questions de révision
- Quelle est la différence entre un moteur CA et un moteur CC?
- Quelle est la différence entre une caméra et un capteur RGB-D?
- Un encodeur rotatif typique utilisé dans un robot mobile à roues pour mesurer la distance qu’il parcourt dispose de 40 fentes. La roue du robot sur laquelle ce capteur est monté a un diamètre de 7 cm. Si le capteur émet une impulsion carrée constante de 7 Hz, quelle est la vitesse du robot en cm/s?
7.8 Lectures supplémentaires
Bien qu’un peu daté, le Sensors for Mobile Robots par H.R Everett et Robot Sensors and transducers par Ray Ruocco offre une couverture complète des capteurs classiques utilisés en robotique. Vision par ordinateur : Algorithms and Applications de Richard Szeliski est un excellent livre d’introduction à la vision par ordinateur en général. Pour plus de concepts liés à la robotique en vision par ordinateur ainsi que pour ceux qui souhaitent lire des sujets plus avancés en robotique, Peter Corke’s Robotics, Vision and Control est fortement recommandé. Le livre comprend de nombreux exemples de code et des boîtes à outils associées dans Matlab®. Programming Computer Vision avec Python : Tools and algorithms for analysing images par Jan Erik Solem fournit de nombreux exemples d’implémentations d’algorithmes de vision basés sur Python. Algorithms de Robert Sedgewick et Kevin Wayne est l’un des meilleurs livres sur le sujet.
Sutton, M., Wolters, W., Peters, W., Ranson, W., and McNeill, S. (1983). Determination of displacements using an improved digital correlation method. Image and vision computing, 1(3), 133–139., https://doi.org/10.1016/0262-8856(83)90064-1
Anandan, P. (1989). A computational framework and an algorithm for the measurement of visual motion. International Journal of Computer Vision, 2(3), 283–310., https://doi.org/10.1007/BF00158167
Chum, O. and Matas, J. (2005). Matching with prosac-progressive sample consensus. In Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, volume 1, pages 220–226. IEEE. http://dx.doi.org/10.1109/CVPR.2005.221
Matas, J. and Chum, O. (2005). Randomised ransac with sequential probability ratio test. In Computer Vision, 2005. ICCV 2005. Tenth IEEE International Conference on, volume 2, pages 1727–1732. IEEE. https://doi.org/10.1109/ICCV.2005.198
Tarsha-Kurdi, F., Landes, T., and Grussenmeyer, P. (2007). Hough-transform and extended RANSAC algorithms for automatic detection of 3D building roof planes from lidar data. In ISPRS Workshop on Laser Scanning 2007 and SilviLaser 2007 , volume 36, pages 407–412. https://www.researchgate.net/publication/301287046_HOUGH-TRANSFORM_AND_EXTENDED_RANSAC_ALGORITHMS_FOR_AUTOMATIC_DETECTION_OF_3D_BUILDING_ROOF_PLANES_FROM_LIDAR_DATA
Schnabel, R., Wessel, R., Wahl, R., and Klein, R. (2008). Shape recognition in 3D point-clouds. In The 16-th International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision, volume 8. Citeseer. https://www.semanticscholar.org/paper/Shape-Recognition-in-3D-Point-Clouds-Schnabel-Wessel/cbb3028963912ce1ad7af106a23c055ce9a56f98
RÉFÉRENCES
Fleet, D. J. and Jepson, A. D. (1990). Computation of component image velocity from local phase information. International journal of computer vision, 5(1), 77–104., https://doi.org/10.1007/BF00056772
Scaramuzza, D. and Fraundorfer, F. (2011). Visual odometry [tutorial]. Robotics & Automation Magazine, IEEE, 18(4), 80–92. https://doi.org/10.1109/MRA.2011.943233
Weiss, S., Scaramuzza, D., and Siegwart, R. (2011). Monocular-SLAM–based navigation for autonomous micro helicopters in GPS-denied environments. Journal of Field Robotics, 28(6), 854–874. http://dx.doi.org/10.1002/rob.20412
Garratt, M. A. and Chahl, J. S. (2008). Vision-based terrain following for an unmanned rotorcraft. Journal of Field Robotics, 25(4), 284. http://dx.doi.org/10.1002/rob.20239
Maimone, M., Cheng, Y., and Matthies, L. (2007). Two years of visual odometry on the mars exploration rovers. Journal of Field Robotics, 24(3), 169–186 https://doi.org/10.1002/rob.20184
Hanna, K. (1991). Direct multi-resolution estimation of ego-motion and structure from motion. In Visual Motion, 1991., Proceedings of the IEEE Workshop on, pages 156–162. IEEE. https://doi.org/10.1007/s10851-011-0267-1
Heeger, D. J. and Jepson, A. D. (1992). Subspace methods for recovering rigid motion i: Algorithm and implementation. International Journal of Computer Vision, 7(2), 95–117. https://doi.org/10.1007/BF00128130
Conroy, J., Gremillion, G., Ranganathan, B., and Humbert, J. (2009). Implementation of wide-field integration of optic flow for autonomous quadrotor navigation. Autonomous Robots, 27(3), 189–198. https://doi.org/10.1007/s10514-009-9140-0
B. Lucas and T. Kanade, « An iterative image registration technique with an application to stereo vision », Proc. DARPA IU Workshop, pp. 121-130, 1981. https://www.researchgate.net/publication/215458777_An_Iterative_Image_Registration_Technique_with_an_Application_to_Stereo_Vision_IJCAI
B.K.P Horn and B.G. Schunk, « Determining optical flow », Artificial Intelligence, vol. 17, pp. 185-203, 1981. https://doi.org/10.1016/0004-3702(81)90024-2
Hähnel, D., Burgard, W., and Thrun, S. (2003). Learning compact 3D models of indoor and outdoor environments with a mobile robot. Robotics and Autonomous Systems, 44(1), 15–27. https://doi.org/10.1016/S0921-8890(03)00007-1
Fischler, M. A. and Bolles, R. C. (1981). Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM , 24(6), 381–395. https://dl.acm.org/doi/10.1145/358669.358692
Jiménez A, Seco F (2005) Ultrasonic localisation methods for accurate positioning. Instituto de Automatica Industrial, Madrid https://www.researchgate.net/publication/228657454_Ultrasonic_Localization_Methods_for_Accurate_Positioning
Takahashi T (2007) 2D localisation of outdoor mobile robots using 3D laser range data. Doctoral dissertation, Carnegie Mellon University https://www.ri.cmu.edu/pub_files/pub4/takahashi_takeshi_2007_1/takahashi_takeshi_2007_1.pdf
Aboelmagd N, Karmat TB, Georgy J (2013) Fundamentals of inertial navigation, satellite-based positioning and their integration. Springer, Berlin https://link.springer.com/content/pdf/10.1007/978-3-642-30466-8.pdf
Kreczmer B (2010) Objects localisation and differentiation using ultrasonic sensors. INTECH Open Access Publisher, West Palm Beach https://doi.org/10.5772/9271
Liste des figures
Figure 7-1 : La boucle « Détecter-Penser-Agir » en robotique
Figure 7-2 : Un capteur de lumière commun (photorésistance)
Figure 7-4 : Le télémètre Hokuyo URG-04LX
Figure 7-5 : Une caméra monoculaire populaire
Figure 7-6 : Une version plus récente du capteur Microsoft® Kinect
Figure 7-8 : un encodeur incrémental rotatif simplifié à 16 fentes
Figure 7-13 : Deux groupes de points 3D représentant deux plans détectés par la méthode RANSAC
