
4 Composants logiciels de base : de Python au contrôle de vision
Damith Herath, Adam Haskard, and Niranjan Shukla
Table des matières
4.3 Python et bases de la programmation
4.3.1 Variables, chaînes et instructions d’affectation
4.3.2 Opérateurs relationnels et logiques
4.4 Programmation orientée objet (POO)
4.7. Étude de cas – Écrire votre premier programme en Python
4.7.1 Une note sur la migration de MATLAB® vers Python
4.8. Principes de base du contrôle de version
4.8.1.2 Configuration d’un référentiel Git
4.8.1.5 Enregistrer les modifications
4.8.1.7 Faire une demande pull
4.8.1.8 Commandes Git courantes
4.9 Applications de conteneurisation
4.1 Objectifs d’apprentissage
Le logiciel est un élément important de la robotique. Dans ce chapitre, nous examinerons certains des concepts clés de la programmation et des outils que nous utilisons en robotique. À la fin de ce chapitre, vous serez en mesure :
- D’acquérir des connaissances sur les langages de programmation couramment utilisés en robotique
- D’explorer les concepts de programmation fondamentaux et de savoir comment les mettre en pratique en utilisant le langage de programmation Python
- De comprendre l’importance du contrôle de version et savoir comment utiliser les commandes de base dans Git
- De sélectionner les outils et techniques adaptés pour développer et déployer efficacement le code.
4.2 Introduction
Qu’il s’agisse d’un robot de qualité industrielle ou d’un robot amateur que vous avez construit, il est difficile d’éviter le codage ou la programmation. Le codage ou la programmation est la manière dont vous donnez des instructions à un robot pour accomplir une tâche. En robotique, vous rencontrerez de nombreux langages de programmation différents, notamment des langages tels que C++, Python et des langages scientifiques tels que MATLAB®. Bien que de nombreux exemples dans ce livre sont basés sur Python, il y aura des occasions où nous utiliserons des extraits de code en C/C++ MATLAB®. Même si nous ne supposons aucune connaissance préalable en programmation, une expérience de codage préalable sera certainement utile pour progresser plus rapidement.
La section suivante présentera brièvement certaines des structures de programmation essentielles. En aucun cas, elles ne sont exhaustives. Il s’agit tout simplement d’introduire quelques concepts de programmation de base qui vous seront utiles pour commencer si vous n’avez pas encore d’expérience en programmation. Nous débuterons avec quelques outils de programmation indispensables tels que les organigrammes et le pseudocode, avant d’aborder les composants de base de la programmation. Si vous possédez déjà une certaine expérience en programmation, vous pouvez ignorer cette section.
Dans les sections suivantes, nous discuterons de deux outils logiciels importants qui se révèleront extrêmement utiles dans la programmation de robots : le contrôle de version et la conteneurisation. Bien que ce soient de bons points de départ, la meilleure façon de renforcer votre confiance et vos compétences est de pratiquer et de vous plonger dans le codage. Ainsi, tout au long du livre, nous proposerons de nombreux exemples pratiques et extraits de code que vous pourrez suivre et essayer, ainsi qu’un ensemble complet de projets à la fin du livre. Une fois que vous avez acquis un certain niveau de confiance, il est important d’explorer de nouveaux problèmes de codage pour développer vos compétences.
4.2.1 Penser au codage
Comme vous l’avez probablement remarqué, nous utilisons les termes « programmation » et « codage » de manière interchangeable, car ils impliquent tous deux de demander à votre robot de réaliser quelque chose de logique. Avant de commencer à programmer, il est essentiel de comprendre le problème que vous souhaitez résoudre et de développer un plan d’action pour construire le code. Les organigrammes et le pseudocode sont deux outils utiles qui vous aideront dans cette phase de planification. Une fois que vous avez établi les grandes lignes du programme, vous devrez choisir le langage de programmation approprié pour la tâche. Pour les tâches où la rapidité d’exécution est importante ou si du matériel de bas niveau est impliqué, un langage tel que C ou C++ est généralement préférable. Cependant, si vous recherchez une approche de prototypage rapide, un langage comme Python peut être plus pratique. Les chercheurs en robotique, quant à eux, ont souvent recours à des langages tels que MATLAB® qui sont orientés vers la programmation mathématique. MATLAB® est un langage propriétaire développé par MathWorks qui propose une variété de boîtes à outils contenant des algorithmes couramment utilisés, des outils de visualisation de données, qui permettent de tester des algorithmes complexes avec un minimum de codage. En plus de ces langages basés sur le code, de nombreux langages de programmation visuels tels que Max/MSP/Jitter, Simulink, LabVIEW, LEGO NXT-G sont régulièrement utilisés par les roboticiens, les artistes et les passionnés pour programmer des robots et des systèmes robotiques. Quel que soit le langage que vous choisissez, les concepts fondamentaux de programmation restent les mêmes.
Peu importe le langage de programmation utilisé, il est courant de considérer un programme comme un ensemble d’entrées qui doivent être traitées pour obtenir la sortie souhaitée (Figure 4-1). En robotique, un cadre similaire est utilisé, appelé la boucle détecter-penser-agir, que nous explorerons en détail dans le chapitre 7.

Figure 4-1 : Un programme simple passe de l’entrée à la sortie après traitement au milieu
4.2.1.1 Organigrammes
Les organigrammes sont un excellent moyen de réfléchir et de visualiser le déroulement de votre programme et de la logique. Ce sont des formes géométriques reliées par des flèches (voir la Figure 4-1 et la Figure 4-2). Les différentes formes géométriques représentent les diverses tâches à effectuer, tandis que les flèches indiquent l’ordre d’exécution, appelé (ligne de flot). Généralement, les organigrammes suivent une disposition de haut en bas et de gauche à droite. Les organigrammes sont un outil pratique pour débuter en programmation. Ils fournissent une représentation visuelle du programme sans avoir besoin de se soucier de la syntaxe spécifique au langage. Cependant, ils peuvent devenir trop encombrants pour les programmes complexes.
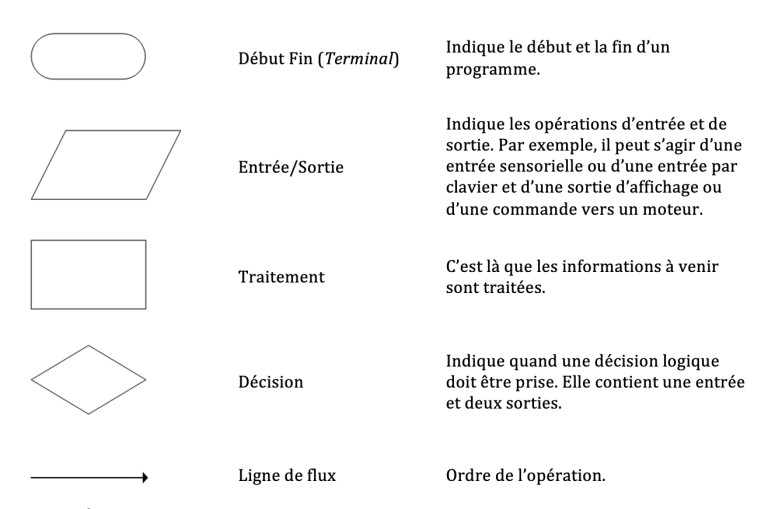
Figure 4-2 : Éléments communs de l’organigramme
Dans les sections suivantes, nous explorerons plus en détail la signification de ces symboles.
4.2.1.2 Pseudocode
Le pseudocode est un autre outil que vous pouvez utiliser pour planifier votre code. Vous pourriez considérer que le pseudocode remplace simplement les formes géométriques évoquées dans la section précédente des organigrammes en utilisant des instructions simples en anglais Contrairement à un langage de programmation spécifique, le pseudocode est un code de programmation sans syntaxe fixe. Par conséquent, le pseudocode est un excellent moyen d’écrire les étapes de votre programme en utilisant un code- similaire, sans référence à une langue de programmation particulière. Par exemple, l’idée d’entrée, de traitement et de sortie pourrait être présentée sous forme de pseudocode simple, comme illustré dans la Figure 4-3. Dans cet exemple, nous avons étendu le programme précédent en englobant le bloc de lecture, de traitement et de sortie dans une structure de boucle répétitive, abordée plus loin dans le chapitre. Dans cette variante du programme, la séquence d’entrée, de traitement et de sortie se répète en boucle jusqu’à ce que l’utilisateur quitte le programme. L’organigramme équivalent est illustré à la Figure 4-4.

Figure 4-3 : Un exemple de pseudocode simple avec une lecture répétitive, traitement, boucle de sortie
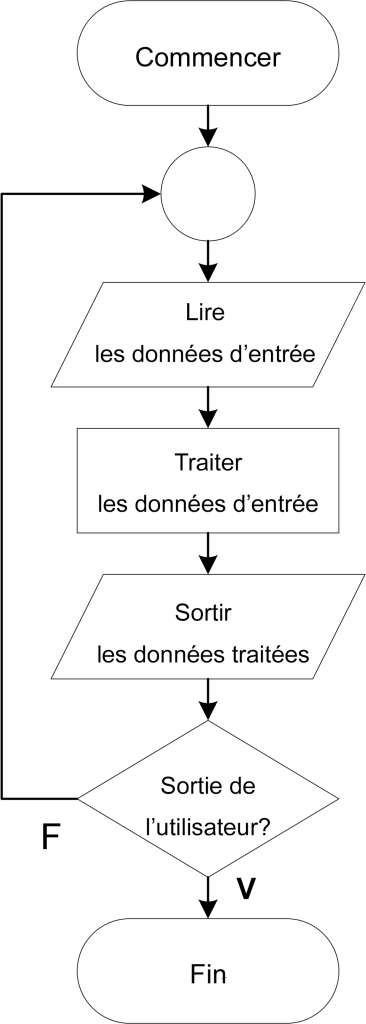
Figure 4-4 : Organigramme d’une boucle simple lecture, traitement, sortie
4.3 Python et bases de la programmation
Publié pour la première fois dans les années 1990, Python est un langage de programmation de haut niveau. Python est un langage interprété, ce qui signifie qu’il est traité lors de son exécution par rapport à un langage compilé qui doit être traité avant d’être exécuté. Python est devenu un langage populaire pour la programmation de robots. Cela peut être dû à son langage facilement lisible, à sa nature visuellement épurée et typée dynamiquement, et à la disponibilité de nombreuses bibliothèques prêtes à l’emploi qui fournissent des fonctionnalités communes telles que des fonctions mathématiques. Python est pratique lorsque vous souhaitez créer rapidement un prototype, car il nécessite un minimum de lignes de code pour réaliser des tâches complexes. Il soulage également un autre casse-tête majeur pour les programmeurs débutants en étant un langage de collecte de déchets. La récupération de place est le processus automatique par lequel la mémoire utilisée par le programme est gérée.
Python identifie les blocs de code en utilisant l’indentation (une tabulation ou un espace blanc au début d’une ligne de code). Contrairement aux langages tels que C/C++ et Java qui utilisent des accolades {} pour délimiter les blocs de code, une indentation correcte est cruciale en Python pour garantir que votre code fonctionne correctement. Cette exigence améliore également la lisibilité et l’esthétique du code.
Passons maintenant en revue quelques concepts de programmation courants en utilisant Python comme exemple de langage.
4.3.1 Variables, chaînes et instructions d’affectation
Python est un langage typé dynamiquement, ce qui signifie que les variables ne sont pas statiquement typées (par exemple, string, float, integer). Les développeurs n’ont donc pas besoin de déclarer les variables avant de les utiliser ni de déclarer leur type. En Python, toutes les variables sont un objet.
Un composant typique de nombreux autres langages de programmation est que les variables sont déclarées dès le départ avec un type de données spécifique, et toute valeur qui lui est attribuée pendant sa durée de vie doit toujours avoir ce type. Python présente un avantage d’accessibilité grâce à l’absence de restriction sur les types de variables. En effet, contrairement à d’autres langages, une variable en Python peut être assignée à une valeur d’un certain type puis à une nouvelle valeur d’un type différent. Chaque valeur en Python possède un type de données. Les autres types de données en Python incluent les nombres, les chaînes, le dictionnaire et bien d’autres. La déclaration de variables en Python est simple et rapide, pouvant être réalisée avec n’importe quel nom ou même avec des noms composés d’alphabet tels que a, ab, abc, etc.
Les chaines sont un type de données utiles et largement utilisées en Python. Nous les créons en mettant les caractères entre guillemets. Python traite les guillemets simples et les guillemets doubles de la même manière. Créer des chaînes est aussi simple que d’attribuer une valeur à une variable. Par exemple :
var1 = ’Hello World!’
var2 = "Banana Robot"
Dans l’exemple ci-dessus, nous constatons deux variables notées par les étiquettes ’var1’ et ’var2’ . Un moyen simple de comprendre consiste à considérer une variable comme un nom attaché à un objet particulier. Pour créer une variable, il vous suffit de lui attribuer une valeur, puis de commencer à l’utiliser. L’affectation est réalisée avec un seul signe égal (=).
4.3.2 Opérateurs relationnels et logiques
Certaines conditions sont requises pour gérer le flux de n’importe quel programme et dans tous les langages de programmation, y compris Python. Les opérateurs relationnels et logiques définissent ces conditions.
Par exemple, et pour le contexte, lorsqu’on vous demande si 3 est supérieur à 2, la réponse est oui. En programmation, la même logique s’applique.
Lorsque le compilateur est fourni avec une condition basée sur une expression, il calcule l’expression et exécute la condition en fonction de la sortie de l’expression. Dans le cas d’expressions rationnelles et logiques, la réponse sera toujours soit Vrai ou Faux.
Les opérateurs sont des symboles conventionnels qui combinent des opérandes pour former une expression. Les opérateurs et les opérandes sont ainsi des facteurs décisifs de la sortie.
Opérateurs relationnels sont utilisés pour définir la relation entre deux opérandes Les exemples sont inférieur à, supérieur ou égal aux opérateurs. Python comprend ces types d’opérateurs et renvoie en conséquence une sortie qui peut être Vrai ou Faux.
1 < 10
Vrai
1 est inférieur à 10, donc la sortie renvoyée est Vrai.
Une liste simple des opérateurs les plus courants :
- Moins que → indiqué par <
- Plus grand que → indiqué par >
- Égal à → indiqué par ==
- Pas égal à → indiqué par !=
- Inférieur ou égal à → indiqué par <=
- Supérieur ou égal à → indiqué par >=
Les opérateurs logiques sont utilisés dans les expressions où les opérandes sont Vrai ou Faux. Les opérandes d’une expression logique peuvent être des expressions qui renvoient Vrai ou Faux lors de l’évaluation.
Il existe trois types de base d’opérateurs logiques :
- AND : Pour l’opération AND, le résultat est Vrai si et seulement si les deux opérandes sont Vrai. Le mot clé utilisé pour cet opérateur est AND.
- OR : Pour l’opération OR, le résultat est Vrai si l’un deux opérandes est Vrai. Le mot clé utilisé pour cet opérateur est OR.
- NOT : Le résultat est Vrai si l’opérande est Faux. Le mot clé utilisé pour cet opérateur est NOT.
4.3.3 Structures de décision
Les structures de décision permettent à un programme d’évaluer une variable et de répondre de manière préétablie. Fondamentalement, le processus de prise de décision répond aux conditions qui se présentent lors de l’exécution du programme, avec des actions conséquentes prises en fonction de ces conditions. Les structures de décision de base évaluent une série d’expressions qui produisent des résultats Vrai ou Faux. Voici les types de séquences de prise de décision proposés par le langage de programmation Python.
- L’instruction if : Une instruction if consiste en une expression booléenne suivie d’une ou plusieurs instructions.
- L’instruction If …else : Une instruction if peut être suivie d’une instruction else facultative, qui s’exécute lorsque l’expression booléenne est FALSE.
- Instruction If imbriqué . Vous pouvez utiliser une instruction if ou else if dans une autre instruction if ou else if.
Vous trouverez ci-dessous un exemple de clause if d’une ligne,
# il s’agit d’un commentaire (commençant par le symbole #).
# Les commentaires sont un élément de documentation important dans la programmation
var = 1300 #a variable assignment
if (var == 1300): print "Value of expression is 1300" #structure de décision en une seule ligne
print "Bye #afficher le mot Bye!
Lorsque le code ci-dessus s’exécute, voici la sortie,
Value of expression is 1300
Bye!
En général, les instructions sont exécutées de manière séquentielle. La première instruction d’une fonction est exécutée en premier, suivie de la seconde et ainsi de suite. Il est utile de considérer le code comme un ensemble d’instructions simples, pas très différent d’une recette de cuisine préférée. Parfois, il est nécessaire d’exécuter plusieurs fois un bloc de code. Une instruction de boucle nous permet d’exécuter une instruction ou un groupe d’instructions plusieurs fois.
4.3.4 Boucles
En Python, il existe généralement trois façons d’exécuter des boucles. Ils offrent tous des fonctionnalités similaires ; cependant, ils diffèrent par leur syntaxe et leur durée de vérification des conditions.
- Boucle While : Répète une instruction ou un groupe d’instructions alors qu’une condition donnée est VRAI. Elle teste la condition avant d’exécuter le corps de la boucle.
- Boucle For : Exécute une séquence d’instructions plusieurs fois et abrège le code qui gère la variable de boucle.
- Boucles imbriquées : Vous pouvez utiliser une ou plusieurs boucles à l’intérieur d’une autre boucle while, for ou do..while.
# boucle while
count = 0
while (count < 3):
count = count + 1 #notez l’indentation pour indiquer que cette section du code est à l’intérieur de la boucle
print("Hello Robot")
Lorsque le code ci-dessus est exécuté, nous nous attendons à voir la sortie suivante :
Hello Robot
Hello Robot
Hello Robot
4.3.5 Fonctions
Une fonction est un bloc de code conçu pour être réutilisable et destiné à effectuer une seule action. Les fonctions offrent aux développeurs une modularité pour leur application ainsi que des blocs de code réutilisables. Une bibliothèque de fonctions bien construite permet de réduire considérablement le temps de développement. Par exemple, Python propose des fonctions telles que print(), mais les utilisateurs peuvent également développer leurs propres fonctions. Ces fonctions sont appelées fonctions définies par l’utilisateur.
Par exemple :
def robot_function():
print("Robot function executed")
# vous pouvez alors appeler cette fonction dans une autre partie de votre programme;
robot_function()
Lorsque vous exécutez le code, ce qui suit s’affiche :
Robot function executed
Vous pouvez transmettre des informations externes à la fonction en tant qu’arguments. Les arguments sont énumérés entre parenthèses après le nom de la fonction.
Par exemple :
def robot_function(robot_name):
print("Robot function executed for robot named " + robot_name)
Nous avons modifié la fonction précédente pour inclure un argument appelé robot_name. Lorsque nous invoquons la nouvelle fonction, nous pouvons désormais inclure le nom du robot comme un argument :
robot_function(‘R2-D2’)
qui se traduira par la sortie suivante :
Robot function executed for robot named R2-D2
4.3.6 Fonction Callback
Une fonction Callback, est une fonction spéciale qui peut être transmise en tant qu’argument à une autre fonction. Cette dernière est conçue pour appeler la fonction Callback définie précédemment Cependant, la fonction Callback n’est exécutée que lorsqu’elle est requise. Les fonctions de rappel trouvent de nombreuses utilisations dans le domaine de la robotique. En particulier, lors de l’utilisation de ROS, on utilise souvent des fonctions Callback pour lire et écrire diverses informations vers et depuis le matériel robotique de manière asynchrone. Un exemple simple illustre les principaux éléments d’une implémentation de fonction Callback.
def callbackFunction(robot_status):
print("Robot’s current status is " + robot_status)
def displayRobotStatus(robot_name, callback):
# cette fonction prend robot_name et une fonction de rappel comme arguments
# Le code pour lire le statut du robot (stocké dans la variable robot_status) va ici
# l’état de lecture est ensuite passé à la fonction de rappel
callback(robot_status)
Vous pouvez maintenant appeler la fonction displayRobotStatus dans votre programme principal
if __name__ == ’__main__’:
displayRobotStatus ("R2-D2", callbackFunc)
4.4 Programmation orientée objet (POO)
La Programmation orientée objet est un paradigme de programmation basé sur le concept d’« objets », qui peuvent contenir à la fois des données sous forme de champs appelés souvent attributs, et du code sous forme de procédures appelé souvent méthodes. Voici une façon simple de penser à cette idée;
- Une personne est un objet qui possède certaines propriétés telles que la taille, le sexe, l’âge, etc.
- L’objet personne a également des méthodes spécifiques telles que se déplacer, parler, courir, etc.
Objet – Unité de base de la programmation orientée objet, qui combine les données et les fonctions en une seule unité.
Classe – Définir une classe, c’est définir un plan pour un objet. Décrit ce que signifie le nom de la classe, en quoi consiste un objet de cette classe et quelles opérations peuvent être effectuées sur un tel objet. Une classe définit les paramètres d’un canevas vide pour un objet.
La POO a quatre concepts de base :
- Abstraction − Fournit uniquement les informations essentielles et masque leurs détails d’arrière-plan. Par exemple, lors de la commande d’une pizza à partir d’une application, les processus principaux de cette transaction ne sont pas visibles pour l’utilisateur.
- Encapsulation − L’encapsulation est le processus de liaison de variables et de fonctions en une seule unité. C’est aussi un moyen de restreindre l’accès à certaines propriétés ou composants. Le meilleur exemple d’encapsulation est la génération d’une nouvelle classe.
- Héritage – Créer une nouvelle classe à partir d’une classe existante s’appelle héritage. En utilisant l’héritage, il est possible de créer une classe enfant qui hérite des propriétés et méthodes de sa classe parent, tout en ayant ses propres propriétés et méthodes supplémentaires. Par exemple, si l’on a une classe Robot avec des propriétés telles que le Modèle et Type, on peut créer deux classes, Mobile_robot et Drone_robot, à partir de ces propriétés, tout en ajoutant des propriétés spécifiques à chaque classe. Ainsi, Mobile_robot pourrait avoir une propriété de nombre de roues tandis que Drone_robot aurait une propriété de nombre de rotors. Ceci s’applique également aux méthodes.
- Polymorphisme – Signifie avoir plusieurs formes. Le polymorphisme se produit lorsqu’il existe une hiérarchie de classes et qu’elles sont liées par héritage.
4.5 Gestion des erreurs
Un programme Python se termine dès qu’il rencontre une erreur. Dans Python, une erreur peut être une erreur de syntaxe (faute de frappe) ou une exception. Les Erreurs de syntaxe se produisent lorsque l’analyseur python détecte une instruction incorrecte dans le programme. Voir l’exemple suivant :
>>> print( 0 / 0 ))
^
SyntaxError: invalid syntax
Le caractère flèche pointe vers l’endroit où l’analyseur a rencontré une erreur de syntaxe. Dans cet exemple, il y avait une parenthèse de trop. Lorsque la parenthèse a été supprimée, le code s’exécutera sans aucune erreur :
>>> print( 0 / 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: integer division or modulo by zero
Cette fois, Python a détecté une erreur d’exception Ce type d’erreur se produit chaque fois qu’un code Python correct génère une erreur. La dernière ligne du message indiquait le type d’erreur d’exception générée. Dans ce cas, il s’agissait d’un ZeroDivisionError. Python a des exceptions intégrées. De plus, il est possible de créer des exceptions définies par l’utilisateur.
4.6 Codage sécurisé
Créer un code sécurisé est essentiel pour protéger les données et maintenir le bon comportement du logiciel. Créer un code sécurisé est une discipline relativement nouvelle, car les développeurs sont principalement chargés d’écrire des fonctions et des sorties, sans nécessairement les sécuriser. Cependant, étant donné la prévalence des exploits, il est important que les développeurs intègrent dès le départ de bonnes pratiques de sécurité.
Voici quelques pratiques de sécurité du développement Python à prendre en compte :
- Utilisez une version à jour de Python : Les versions obsolètes ont été corrigées avec des mises à jour de la vulnérabilité. Ne pas intégrer ces mises à jour dans l’environnement Python peut laisser les vulnérabilités exposées à des exploitations.
- Créez la base de code dans un environnement Sandbox : L’utilisation d’un environnement Sandbox empêche les dépendances Python malveillantes de passer en production. Si des progiciels malveillants sont présents dans les environnements Python, l’utilisation d’un environnement virtuel permettra d’isoler les progiciels de la base de code de production.
- Importez correctement les progiciels : Lorsque vous travaillez avec des modules Python externes ou internes, veillez à les importer en utilisant les bons chemins. Il existe deux types de chemins d’importation en Python : absolus et relatifs. De plus, il existe deux types d’importations relatives : implicites et explicites. Les importations implicites ne spécifient pas le chemin de la ressource relatif au module actuel, tandis que les importations explicites spécifient le chemin exact du module que vous souhaitez importer. L’importation implicite a été désapprouvée et supprimée de Python 3, car si le module spécifié est trouvé dans le chemin du système, il sera importé, ce qui pourrait être très dangereux, car il est possible qu’un module malveillant portant un nom identique se trouve dans une bibliothèque open-source et puisse trouver son chemin vers le chemin du système. Si le module malveillant est trouvé avant le module réel, il sera importé et utilisé pour exploiter les applications dans leur arbre de dépendance. Il est important d’assurer une importation absolue ou des importations relatives explicites, car cela garantit l’authenticité et l’intégrité du module attendu.
- Utilisez les requêtes HTTP Python avec précaution : Il est recommandé de faire preuve de prudence lors de l’envoi de requêtes HTTP et de bien comprendre comment la bibliothèque que vous utilisez gère la sécurité pour éviter les problèmes de sécurité. Lorsque vous utilisez une bibliothèque de requêtes HTTP courante telle que Requests, il est déconseillé de spécifier des versions antérieures dans votre fichier requirements.txt, car avec le temps, des versions obsolètes du module peuvent être installées. Pour éviter cela, assurez-vous d’utiliser la version la plus récente de la bibliothèque et vérifiez si elle gère la vérification SSL de la source.
- Il est important d’identifier les progiciels exploités et malveillants.
Les progiciels sont utiles, car ils permettent de gagner du temps en évitant de créer des artefacts à partir de zéro à chaque fois. Les progiciels Python peuvent être facilement installés via l’outil d’installation de progiciels Pip. Cependant, il convient de noter que les progiciels Python sont généralement publiés sur PyPI, un référentiel de code pour les progiciels Python qui n’est pas soumis à un examen ou à un contrôle de sécurité. Cela signifie que PyPI peut facilement publier du code malveillant.
Afin d’éviter d’avoir des progiciels exploités dans votre code, il est important de vérifier chaque progiciel Python que vous importez. De plus, il est recommandé d’utiliser des outils de sécurité dans votre environnement pour analyser vos dépendances Python et éliminer les progiciels exploités.
4.7 Étude de cas – Écrire votre premier programme en Python
Pour commencer à expérimenter avec Python, vous pouvez télécharger la version actuelle du programme Python à partir du site Web Python. Suivez les instructions du site Web pour installer la version recommandée pour votre système d’exploitation. Une fois que vous avez installé Python, vous pouvez utiliser le shell Python (ligne de commande) pour créer un environnement de programmation interactif, comme illustré dans la Figure 4-5.

Figure 4-5 : La ligne de commande Python
Dans n’importe quel langage de programmation, le programme Hello World est un code partagé par tous les développeurs. Vous pouvez également créer votre propre programme « Hello World ». Voici un exemple classique ci-dessous. . Veuillez noter que le symbole # indique une ligne de commentaire qui n’est pas lue par Python comme du code à exécuter. Au lieu de cela, il est destiné à être compris par les programmeurs afin qu’ils puissent facilement comprendre ce que chaque ligne de code est censée faire. La clé d’une bonne collaboration et d’une bonne hygiène de développement est de bien commenter régulièrement.
# Ce programme imprime Hello, world!
print(’Hello, world!’)
Sortie
Hello, world!

Figure 4-6 : Le programme Hello, World exécuté de manière interactive dans une fenêtre de ligne de commande Python
4.7.1 Une note sur la migration de MATLAB® vers Python
En vous attardant sur la programmation robotique et l’écriture d’algorithmes, vous remarquerez que de nombreux exemples sont écrits en utilisant MATLAB®, en particulier dans le milieu universitaire pour les raisons mentionnées précédemment. Cependant, il existe des raisons impérieuses d’utiliser Python au lieu d’un langage propriétaire comme MATLAB. L’une des principales raisons étant le coût d’acquisition de MATLAB et des boîtes à outils associées. Python vous permet de distribuer facilement votre code sans vous soucier que vos utilisateurs finaux aient besoin d’acheter des licences MATLAB® pour exécuter votre code. De plus, Python étant un langage de programmation à usage général, il vous offre un meilleur environnement de développement pour les projets ciblant un large public d’utilisation et de déploiement.
Si vous envisagez de migrer du code de MATLAB® vers Python, la bonne nouvelle est que les deux langages sont « très similaires ». Cela permet une transition relativement facile de MATLAB vers Python. L’une des principales raisons de la popularité de MATLAB est son large éventail de boîtes à outils bien conçues par des experts dans le domaine. Par exemple, il existe plusieurs boîtes à outils populaires liées à la robotique, notamment la Boîte à outils robotique développée par Peter Corke. Ces boîtes à outils proposent des fonctions mathématiques spécifiques qui permettent de réduire le temps requis pour élaborer un nouveau code lors de la création ou du test de nouvelles idées pour votre robot. Python offre également un mécanisme similaire pour élargir ses fonctionnalités via des progiciels Python. Par exemple, l’un des points forts de MATLAB est sa capacité native à travailler avec des matrices et des tableaux (note complémentaire : les matrices et les tableaux jouent un rôle important en programmation robotique!).
Python, étant un langage à usage général, ne dispose pas de cette capacité intégrée. Cependant, un progiciel disponible en Python appelé NumPy permet de résoudre ce problème en utilisant des tableaux multidimensionnels qui offrent la possibilité d’écrire des opérateurs matriciels rapides, efficaces et concis, comparables à MATLAB. Au fur et à mesure que vos compétences en robotique et en programmation s’améliorent, il serait rentable de consacrer du temps à explorer les similitudes et les différences entre ces deux langages et à comprendre quand utiliser l’un ou l’autre. La Figure 4-7 montre notre simple programme « Hello World » en cours d’exécution dans une fenêtre de ligne de commande MATLAB®. Pouvez-vous repérer les différences entre les syntaxes de notre exemple Python dans la Figure 4-6 ?
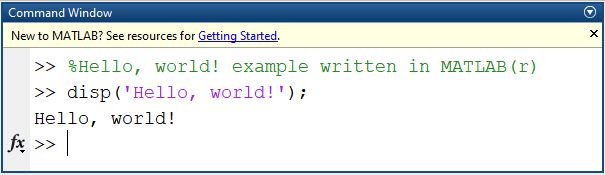
Figure 4-7 : Le programme Hello, World exécuté de manière interactive dans une fenêtre de ligne de commande MATLAB
4.8 Principes de base du contrôle de version
Le Contrôle de version consiste à gérer les modifications apportées à la base de code au fil du temps et potentiellement entre plusieurs développeurs travaillant sur le même projet. Cette pratique est également appelée contrôle de source. Le contrôle de version offre un instantané du développement et permet de suivre l’historique des commits du code. Il permet également de fusionner les contributions de code provenant de plusieurs sources et de gérer les conflits de fusion.
Un système de contrôle de version (ou système de gestion de contrôle de source) offre une suite de fonctionnalités permettant aux développeurs de suivre les modifications de code et de revenir à des versions précédentes de la base de code. De plus, il fournit une plate-forme collaborative pour le travail d’équipe tout en vous permettant de travailler de manière indépendante jusqu’à ce que vous soyez prêt à enregistrer votre travail. Un système de contrôle de version vise à vous aider à rationaliser votre travail tout en fournissant un emplacement centralisé pour votre code. Le contrôle de version est essentiel pour garantir que les progiciels de code testés et approuvés sont déployés dans l’environnement de production.
4.8.1 Git
Git est un puissant système de contrôle de version source ouverte. Contrairement à d’autres systèmes de contrôle de version qui considèrent le contrôle de version comme une liste de modifications basées sur des fichiers, Git considère ses données davantage comme une série d’instantanés d’un système de fichiers miniature. Un instantané représente l’état de tous les fichiers à un moment donné. Git stocke les références à ces instantanés dans le cadre de sa gestion des versions.
Les équipes de développeurs utilisent Git de différentes manières en raison de son modèle distribué et accessible. Il n’y a pas de politique imposée quant à la manière dont une équipe doit utiliser Git. Cependant, les projets développent généralement leurs propres processus et politiques. Le seul impératif est que l’équipe comprenne et adhère au processus du flux de travail qui permet de valider fréquemment le code et de minimiser les conflits de fusion.
Un projet avec Git se compose de trois zones : l’arbre de travail, l’environnement de simulation et le répertoire Git.
Au fur et à mesure que vous progressez dans votre travail, vous placez généralement vos validations dans l’environnement de simulation, puis vous les validez dans le répertoire (ou référentiel) Git. À tout moment, vous pouvez vérifier vos modifications à partir du répertoire Git.
4.8.1.1 Installation de Git
Pour vérifier si Git est déjà fourni avec votre système d’exploitation, exécutez la commande suivante à l’invite de commande :
git --version
Pour installer Git, rendez-vous sur le site de téléchargement et sélectionnez la version appropriée pour votre système d’exploitation, puis suivez les instructions.
4.8.1.2 Configuration d’un référentiel Git
Pour initialiser un référentiel Git dans un dossier de projet sur le système de fichiers, exécutez la commande suivante depuis le répertoire racine de votre dossier :
git init
Sinon, pour cloner un référentiel Git distant dans votre système de fichiers, exécutez la commande suivante :
git clone <remote_repository_url>
Les référentiels Git fournissent des URL SSH au format git@host:user_name/repository_name. git
Git fournit plusieurs commandes pour cette synchronisation avec un référentiel distant :
Git remote : Cette commande permet de gérer les connexions à des référentiels distants, y compris la création, la visualisation, la mise à jour et la suppression de ces connexions aux référentiels distants. Elle fournit également des alias pour référencer ces connexions plutôt que d’utiliser leur URL complète.
La commande ci-dessous permet de répertorier toutes les connexions à des référentiels distants avec leur URL.
git remote -v
La commande ci-dessous permet de créer une nouvelle connexion à un référentiel distant.
git remote add <repo_name> <repo_url>
La commande ci-dessous permet de supprimer une connexion à un référentiel distant.
git remote rm <repo_name>
La commande ci-dessous permet de renommer une connexion distante de repo_name_1 à repo_name_2
git remote rename <repo_name_1> <repo_name_2>
Lors du clonage d’un référentiel distant, la connexion au référentiel distant est appelée origine.
Pour extraire (pull) les modifications d’un référentiel distant, utilisez soit Git fetch ou Git pull
La commande ci-dessous permet de récupérer une branche spécifique du référentiel distant.
git fetch <repo_url> <branch_name>
où repo_url est le nom du référentiel distant et branch_name est le nom de la branche.
Alternativement, pour récupérer toutes les branches, utilisez la commande ci-dessous :
git fetch —all
La commande ci-dessous permet d’extraire (pull) les modifications du référentiel distant.
git pull <repo_url>
La commande ci-dessus permet de récupérer la copie du référentiel distant de votre branche actuelle et fusionnera les modifications dans votre branche actuelle.
Si vous souhaitez voir ce processus en détail, utilisez le drapeau verbeux, comme indiqué ci-dessous :
git pull —verbose
Comme git pull utilise la fusion comme stratégie par défaut, si vous souhaitez utiliser rebase à la place, exécutez la commande ci-dessous :
git pull —rebase <repo_url>
Pour pousser les modifications vers un référentiel distant, utilisez git push, comme décrit ci-dessous :
git push <repo_name> <branch_name>
Où repo_name est le nom du référentiel distant et branch_name est le nom de la branche locale.
4.8.1.3 Git SSH
Une clé SSH est un moyen d’authentification pour le protocole Secure Shell (SSH) utilisé dans les réseaux. Cette technologie utilise une paire de clés – une clé publique et une clé privée – pour initier une connexion sécurisée entre des parties distantes.
Les clés SSH sont générées à l’aide d’un algorithme de cryptographie à clé publique.
- Si vous souhaitez générer une clé SSH sur un Mac, vous pouvez utiliser la commande suivante :
ssh-keygen -t rsa -b 4096 -C "your_email@domain"
2. Après avoir été invité à spécifier le chemin de stockage de la clé, choisissez un fichier dans lequel vous voulez l’enregistrer.
3. Créez une phrase de passe sécurisée.
4. Ajoutez la clé SSH nouvellement générée au ssh-agent
ssh-add -K <file_path_from_step_2>
4.8.1.4 Git archive
Pour exporter un projet Git vers une archive, exécutez la commande suivante :
git archive --output=<output_archive_name> --format=tar HEAD
La commande ci-dessus génère une archive à partir du HEAD actuel du référentiel. Le HEAD fait référence au commit actuel.
4.8.1.5 Enregistrer les modifications
Lorsque vous modifiez votre code en local, que ce soit pour développer de nouvelles fonctionnalités ou corriger des bogues, vous aurez besoin de les simuler avant la mise en production. Pour ce faire, veuillez exécuter la commande suivante pour chaque fichier que vous souhaitez ajouter à l’environnement de simulation :
git add <file_name>
git commit -m <commit_message>“
La première commande permet de placer vos modifications dans l’environnement de simulation, tandis que la deuxième commande crée un instantané de ces modifications qui peut être envoyé au référentiel distant.
Si vous souhaitez ajouter tous les fichiers en une seule fois, vous pouvez utiliser la variante de Git add avec l’option —all.
Une fois que vous avez ajouté le(s) fichier(s) à la zone de préparation, ils sont suivis.
4.8.1.6 Synchronisation
Après avoir validé les modifications sur votre référentiel local, il est temps de synchroniser votre référentiel distant Git avec les validations effectuées localement. Veuillez consulter les commandes de synchronisation mentionnées au début de cette section pour effectuer une synchronisation.
4.8.1.7 Faire une demande pull
Une demande pull (extraction) est utilisée pour informer l’équipe de développement (ou les réviseurs assignés) des modifications apportées, telles qu’une nouvelle fonctionnalité ou une correction de bogue, afin qu’ils puissent examiner les modifications de code (ou commits) et les approuver, les refuser entièrement ou demander des modifications supplémentaires.
Dans le cadre de ce processus :
- Un membre de l’équipe crée une nouvelle branche locale (ou crée sa branche locale à partir d’une branche distante existante) et y apporte des modifications.
- Une fois les modifications finalisées, le membre de l’équipe les transmet à leur branche distante dans le référentiel distant.
- Le membre de l’équipe crée une demande pull (extraction) en utilisant le système de contrôle de version. Au cours de cette procédure, il sélectionne les branches sources et de destination et affecte des réviseurs.
- Le ou les réviseurs affecté(s) discutent des modifications de code en équipe à travers la plate-forme de collaboration intégrée au système de contrôle de version, et prennent finalement une décision d’accepter ou de refuser les modifications en totalité ou en partie.
- L’étape 4 ci-dessus peut passer par plusieurs autres cycles ou de révisions.
- Une fois que toutes les modifications ont été acceptées (ou approuvées) à la fin du processus de révision, le membre de l’équipe fusionne la branche distante dans le référentiel de code, ce qui ferme la demande pull (extraction).
Figure 4-8 : Exemples de demandes pull
4.8.1.8 Commandes Git courantes
Le tableau ci-dessous répertorie certaines commandes Git couramment utilisées qui sont utiles de retenir. La Figure 4-9 illustre le sens d’exécution relatif de certaines de ces commandes.
| Configurez votre nom d’utilisateur et votre adresse courriel avec Git | git config --global user.name “<user_name>” |
|
Initialiser un référentiel Git |
git init |
| Cloner un référentiel Git | git clone <repo_url> |
| Se connecter à un référentiel Git distant | git remote add origin <remote_server> |
| Ajouter des fichiers à un référentiel Git | git add <file_name> |
| Vérifier l’état des fichiers | git status |
| Enregistrer les modifications dans le référentiel local | git commit -m "<message>" |
| Pousser les modifications vers le référentiel distant | git push origin master |
| Passer d’une branche à l’autre | git checkout -b <branch_name>
|
| Mise à jour à partir du référentiel distant | git pull
|
| Remplacer les modifications locales | git checkout -- <file_name>
|
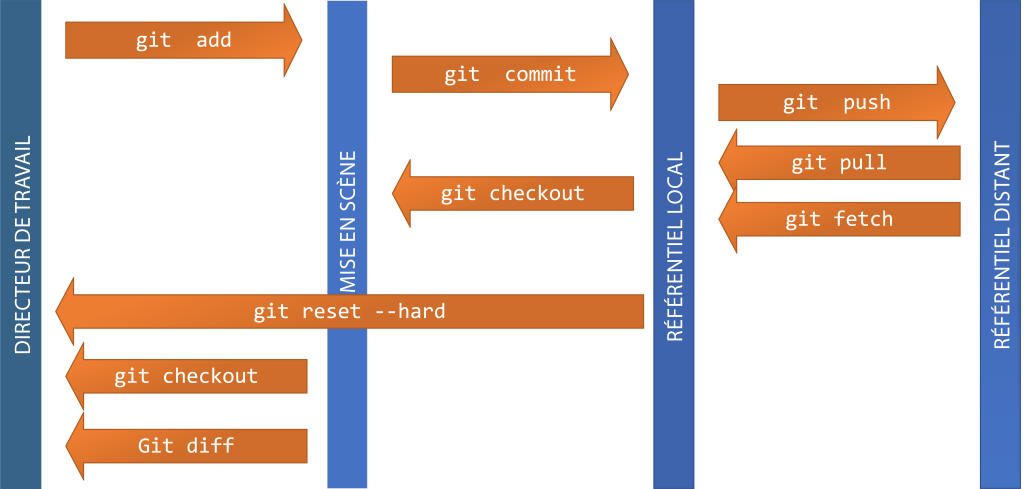
Figure 4-9 : Commandes Git courantes et directions d’exécution relatives
4.9 Applications de conteneurisation
Une variation mineure dans la version d’une bibliothèque peut modifier le fonctionnement de votre application et provoquer un résultat inattendu. Heureusement, en conteneurisant votre application, elle peut être exécutée de manière identique sur n’importe quel ordinateur ou environnement de travail où elle est déployée. Vous pouvez considérer la conteneurisation comme une solution efficace aux machines virtuelles.
Docker est un excellent outil à considérer pour la conteneurisation. L’une des raisons principales qui ont poussé la communauté de développement à adopter Docker est que si vous conteneurisez votre application et transférez l’image dans l’environnement de votre collaborateur, l’application aura les mêmes performances sur les deux dispositifs. En effet, le conteneur contient effectivement toutes les dépendances requises par l’application.
4.10 Résumé du chapitre
Le chapitre a débuté par une présentation des structures courantes utilisées en programmation, en prenant Python comme exemple de langage. L’objectif était de fournir un point de départ pour les lecteurs non-initiés aux bases de la programmation, ou de rafraîchir rapidement la mémoire de ceux qui reprennent le codage après une certaine période d’inactivité. Nous avons également discuté de quelques outils utiles pour faciliter la réflexion computationnelle, tels que les organigrammes et le pseudocode. Nous avons ensuite traité plusieurs concepts clés, tels que la POO, la gestion des erreurs, la programmation sécurisée et le contrôle de version. Tout programmeur en robotique compétent doit maîtriser ces aspects. Encore une fois, notre objectif était de vous donner un aperçu de concepts fondamentaux à approfondir et à développer. Finalement, nous avons évoqué la conteneurisation comme étant un moyen efficace de déployer votre code sur diverses plates-formes et systèmes d’exploitation. La section Projets du livre offrira d’autres opportunités pour pratiquer et explorer ces concepts plus en profondeur.
4.11 Questions de révision
- Quels sont certains des langages de programmation couramment utilisés en robotique?
- Vous devez afficher le modèle suivant sur un écran. Élaborez le pseudocode d’un algorithme approprié pour cette tâche.
*
* *
* * *
* * * *
* * * * *
- Convertissez le pseudocode développé dans le chapitre 2. ci-dessus en une implémentation Python.
- Quels sont les quatre concepts de base de la POO?
- Qu’est-ce que Git et pourquoi est-ce important?
4.12 Lectures supplémentaires
Il existe tellement de ressources disponibles en ligne ainsi que d’excellents livres écrits sur chacun des sujets abordés dans ce chapitre qu’il est difficile de suggérer une liste de lectures appropriées. Vous pouvez consulter le site Web du livre pour avoir accès à une liste de ressources à jour. Les sources suivantes ont été particulièrement utiles pour la rédaction de ce chapitre :
- Programmation Python [1-5]
- Git [6]
- Conteneurisation [7]
RÉFÉRENCES
[1] « Welcome to Python.org, » Python.org, May 29, 2019. https://www.python.org/.
[2] « Python Tutorial, » www.tutorialspoint.com. https://www.tutorialspoint.com/python (Consulté le 22 déc. 2021).
[3] « How to Containerize a Python Application, » Engineering Education (EngEd) Program | Section. https://www.section.io/engineering-education/how-to-containerize-a-python-application/ (Consulté le 22 déc. 2021).
[4] « Python Exceptions: An Introduction – Real Python, » realpython.com. https://realpython.com/python-exceptions (Consulté le 22 déc. 2021).
[5] « Python Security Practices You Should Maintain, » SecureCoding, 18 mai, 2020. https://www.securecoding.com/blog/python-security-practices-you-should-maintain/.
[6] Atlassian, « Git Tutorials and Training | Atlassian Git Tutorial, » Atlassian. https://www.atlassian.com/git/tutorials (Consulté le 22 déc. 2021).
[7] Docker, « What is a Container? | Docker, » Docker, 2013. https://www.docker.com/resources/what-container.
Liste des figures
Figure 4-1 : Un programme simple passe de l’entrée à la sortie après traitement au milieu
Figure 4-2 : Éléments communs de l’organigramme
Figure 4-4 : Organigramme d’une boucle simple lecture, traitement, sortie
Figure 4-5 : La ligne de commande Python
Figure 4-8 : Exemples de demandes pull
Figure 4-9 : Commandes Git courantes et directions d’exécution relatives
