
13 Robots sociaux : Principes de la conception d’interaction et des études sur les utilisateurs
Janie Busby Grant and Damith Herath
Table des matières
13.1 Objectifs d’apprentissage
Une perspective de l’industrie : Martin Leroux, ingénieur d’application sur le terrain. Kinova inc.
13.3 Robots de collaboration (Cobots), robots sociaux et interaction humain-robot (IHR)
13.4 Pourquoi effectuer des recherches ?
13.4.1 Motivation pour la recherche
13.5 Décider de vos variables de recherche
13.5.3 Compromis pertinence-sensibilité
13.5.6 Recherche corrélationnelle
13.5.7 Recherche expérimentale
13.5.8 Conception inter-sujets et intra-sujets
13.5.10 Examens et méta-analyses
13.5.11 Quelle est la meilleure conception de recherche ?
13.6 Échantillonnage, fiabilité et validité
13.6.4 Les éventualités où la validité peut être compromise
13.6.5 Façons de résoudre les problèmes de validité
13.7.1 L’éthique et les comités d’éthique
13.7.2 Principes éthiques en recherche
13.7.2.2 Minimiser les risques
13.7.3 Données, analyse et interprétation
13.7.3.2 Statistiques descriptives
13.7.3.3 Statistiques inférentielles
13.7.3.4 Présentation des résultats
13.7.4 Erreurs et pièges courants
13.1 Objectifs d’apprentissage
robotique sociale. A la fin de ce chapitre, vous :
- Serez en mesure de décrire pourquoi vous effectuez ce projet de recherche, y compris votre motivation pour mener la recherche, le public visé par vos résultats et les principales questions de recherche que vous allez aborder.
- Serez en mesure d’identifier les variables clés sur lesquelles vous souhaitez vous concentrer et comprendre comment mettre en œuvre ces variables dans des environnements de recherche réels.
- Serez en mesure de reconnaître différents types de modèles de recherche, déterminer les avantages et les inconvénients de chacun et lequel est le plus approprié pour une situation donnée.
- Apprendrez les concepts de validité et de fiabilité, et serez en mesure à la fois d’identifier et de résoudre les problèmes qui peuvent survenir.
- Comprendrez les principes clés à prendre en compte lors de la conception et de la conduite d’une recherche éthique.
- Serez en mesure d’identifier les facteurs clés lors de l’analyse et de l’interprétation des données.
13.2 Introduction
Ce chapitre examine quand, pourquoi et comment vous pouvez effectuer des recherches axées sur l’utilisateur lorsque vous travaillez avec des robots. Bien que des recherches passionnantes et de haute qualité sur l’interaction humain-robot soient effectuées dans des laboratoires et des environnements réels à travers le monde entier, ceux qui travaillent dans le domaine de la robotique se sentent souvent incertains ou non préparés à mener des recherches axées sur l’utilisateur, car la conception et l’analyse de la recherche ne sont généralement pas incluses dans les cours de robotique de premier cycle. La réalisation d’études de recherche bien conçues peut vous permettre d’identifier les problèmes potentiels, les avantages et les résultats inattendus des interactions réelles entre les robots et les utilisateurs, et peut également fournir des preuves d’efficacité et d’impact. Avoir la capacité de concevoir et de mener des études utilisateur avec confiance et compétence avec des robots sera un avantage dans une multitude de rôles en milieu de travail.
Ce chapitre est une introduction et un guide pratique pour effectuer des recherches sur les interactions humain-robot. Dans ce chapitre, nous examinons pourquoi vous devriez effectuer des recherches pour examiner l’interaction humain-robot, comment vous pouvez identifier le meilleur plan de recherche pour répondre à votre question, et sélectionner et mesurer les variables appropriées. Tout au long du chapitre, nous fournissons des exemples de projets de recherche pertinents dans le monde réel. Bien que nous ne puissions uniquement « qu’effleurer la surface » de chaque sujet dont nous discutons dans ce seul chapitre, nous vous encourageons à approfondir les questions qui vous intéressent et à utiliser les outils de ce chapitre pour mieux comprendre et mettre en œuvre des projets de recherche bien conçus sur l’interaction humain-robot.
Une perspective de l’industrie :
Martin Leroux, ingénieur d’application sur le terrain.
Kinova inc.

J’étais en train d’étudier en but d’acquérir mon baccalauréat en génie physique, mais je n’étais pas très enthousiaste, car je trouvais que cela était trop abstrait. À cette époque, j’ai eu la chance de trouver un stage dans un laboratoire de robotique qui m’a attiré, non pas pour mes compétences en robotique, mais plutôt pour les compétences avancées en mathématiques que j’avais développées en physique. Ce stage a été un véritable déclic pour moi. J’ai enfin pu expliquer à ma famille ce que je faisais avec des termes qu’ils pouvaient comprendre. J’ai initialement exploré ce domaine pour ressentir une satisfaction personnelle, mais j’ai fini par y rester en raison de son immensité et de ma volonté de continuer à apprendre constamment de nouvelles choses.
Au début de mon emploi chez Kinova, j’évaluais des méthodes alternatives de contrôle pour aider les utilisateurs de nos robots d’assistance à bien les manipuler. Une fois, j’ai commencé à travailler sur l’étude de lisibilité optimale, et un de mes collègues a insisté pour que nous laissions un de nos utilisateurs l’essayer dès que possible; j’ai trouvé que c’était trop tôt, car j’ai également des yeux. Lorsque j’ai demandé pourquoi il était si insistant, il m’a expliqué que leur équipe avait passé plusieurs semaines à développer un programme pour aider les utilisateurs assistés à boire directement à partir d’une bouteille; le programme permettait d’ajuster la rotation du bras, la vitesse de levage et d’autres paramètres pour que l’utilisateur puisse boire facilement et sans effort. Ensuite, lorsqu’ils ont fini et sont allés le présenter à un utilisateur et sa réaction a été : « Oh, je ne prendrais jamais la peine de faire ça. J’utilise juste une paille ». Cette simple réaction a annulé des semaines de travail. Désormais, nous impliquons toujours nos utilisateurs finaux dès le départ.
13.3 Robots de collaboration (Cobots), robots sociaux et interaction humain-robot (IHR)
Considéré comme le père de la robotique, l’ingénieur et entrepreneur, Joseph Engelberger, après avoir commercialisé le premier bras de robot industriel, a précisé dans son livre « Robotics in Service » que l’orientation principale de l’industrie devrait être vers le développement de ce qu’on appelle les robots de service. Il a soutenu que les développements technologiques dans la perception des robots et l’intelligence artificielle devraient permettre le remplacement du travail humain à forte intensité de main-d’œuvre et désagréable, par des dispositifs robotiques. En fait, une partie considérable de ce travail humain de routine est désormais automatisée à l’aide de technologies robotiques. Ce faisant, les robots se sont implantés de plus en plus dans les espace humains. Cela oblige les concepteurs de ces dispositifs robotiques à prendre en compte des éléments tels que la sécurité perçue, les facteurs humains et l’ergonomie en plus des capacités d’ingénierie des robots. Les cousins modernes de l’Unimate original (comme les robots Kinova Gen3) incarnent ces technologies naissantes, en offrant la possibilité d’interagir directement et de travailler aux côtés des humains de manière sûre et intelligente. Une nouvelle catégorie de robots industriels appelée robots collaboratifs ou cobots, est en train d’émerger Ces technologies sont considérées comme appartenant à la quatrième révolution industrielle (industrie 4.0) qui représente l’évolution des technologies et des pratiques de fabrication industrielle traditionnelles combinées aux technologies intelligentes émergentes telles que l’Internet des objets (IoT), l’informatique en nuage et l’intelligence artificielle (IA).
D’autre part, les origines du mot « robotique » et comme nous le voyons dans la culture populaire, les robots sont censés être le reflet de l’humanité. Comme nous en avons discuté précédemment, les humains entretiennent l’idée de machines ressemblant à des humains depuis des millénaires. Avec les progrès récents dans des domaines connexes de l’informatique et du matériel, la communauté des ingénieurs s’intéresse de plus en plus à l’exploration du développement technique de robots socialement intelligents. Nous avons déjà vu plusieurs publicités sur des robots artificiellement socialement intelligents apparaissant sur le marché avec divers succès. Ce nouveau genre de machines appelé « robots sociaux » sont destinées à interagir avec les humains à un niveau cognitif et émotionnel plus élevé, par rapport à un robot industriel typique dans une usine.
Dans les deux cas, les robots sont de plus en plus tenus d’interagir avec les humains, et surtout avec les utilisateurs finaux qui ne sont pas techniquement formés pour faire fonctionner des robots (comme c’est actuellement le cas avec les robots de l’ère industrielle). Comme nous l’avons déjà vu au chapitre 3, une réflexion empathique est nécessaire lors de la conception de tels robots en gardant à l’esprit les utilisateurs finaux. Et d’un autre côté, avant de déployer ces robots, il faut non seulement valider les fonctions d’ingénierie du robot, mais aussi sa capacité à interagir avec les humains comme prévu. Cette interaction nécessite une compréhension de la psychologie humaine et une expertise disciplinaire associée. L’étude de l’interaction humain-robot est donc un domaine émergent qui non seulement englobe de nombreux domaines de l’ingénierie, mais offre un concept disciplinaire plus large qui couvre la psychologie, la sociologie, la conception et les sciences humaines. En conclusion, IHR (Interaction humain-robot) est le nouveau domaine qui attire considérablement l’attention de la communauté robotique avec plusieurs revues et conférences clés consacrées déjà au sujet, y compris la Conférence internationale ACM/IEEE sur l’interaction humain-robot et la Conférence internationale sur la robotique sociale et leurs journaux respectifs, ACM Transactions on Human-Robot Interaction et International Journal of Social Robotics.
13.4 Pourquoi effectuer des recherches?
Tout projet de recherche devrait commencer par le « pourquoi? ». Pourquoi voulez-vous ou devez-vous effectuer une recherche, quelles sont les questions auxquelles vous souhaitez obtenir des réponses, qu’est-ce que les résultats vous permettront de savoir ou de faire, et qui sera intéressé par les réponses que vous générez?
13.4.1 Motivation pour la recherche
Vos raisons pour effectuer la recherche peuvent être diverses et pourraient inclure :
- Vous souhaitez savoir comment les personnes interagissent avec le robot afin de l’améliorer.
- Vous n’êtes pas sûr de la manière dont le robot fonctionnera dans des situations réelles.
- Vous avez besoin de fournir aux investisseurs des preuves que votre produit sera un succès.
- Vous travaillez sur un projet dans un milieu universitaire ou dans un milieu de recherche.
- Votre patron/superviseur/partenaire de financement vous a dit de le faire!
Toutes ces raisons et bien d’autres sont des raisons légitimes pour effectuer une recherche, mais la façon dont vous concevez votre projet dépendra de votre « pourquoi », qui détermine votre question de recherche et votre public. Par exemple, vous pourriez avoir des questions sur : l’efficacité (la performance du robot dans des conditions contrôlées), l’efficience (à quel point le robot réussit-il dans le monde réel), la sécurité (à la fois technique et perçue par l’utilisateur), ou les perceptions des personnes qui interagissent avec les robots (telles que les évaluations concernant l’amabilité et l’animéité).
|
Exemples de recherche : Pourquoi et public cible Sylax : Un projet universitaire de recherche en robotique
Tommy : Un robot conçu par une jeune entreprise pour être commercialisé
Coramand : Un produit robotique d’une entreprise technologique pour un déploiement industriel à grande échelle
|
13.4.2 Public cible
Qui est la cible visée des résultats de la recherche? N’oubliez pas qu’il peut y avoir plusieurs utilisations et auditoires pour votre résultat d’une recherche particulière.
En général, la recherche que vous menez contribuera à améliorer vos propres connaissances, de sorte que vous êtes souvent votre premier public. Réfléchissez soigneusement à ce que vous devez savoir pour faire avancer le projet – quelles informations seront directement utiles à la prochaine étape de votre projet? Il arrive fréquemment que les chercheurs soient pris au piège de leur propre intelligence et créent des expériences complexes, seulement pour se rendre compte qu’ils ont altéré leur conception au point que les réponses obtenues ne répondent plus complètement à leurs questions de recherche initiales! Revenez toujours à votre question clé de recherche et à la réponse qui vous permettra de conclure.
Si vous êtes un étudiant ou un chercheur universitaire, votre public cible sera également d’autres personnes dans votre domaine académique. Vous devez être familier avec la littérature clé, et dans un domaine en évolution rapide comme la robotique, cela signifie également assister aux principales conférences, lire de nouveaux extraits de projets connexes, participer à des concours, à de nouveaux projets commerciaux et à des jeunes entreprises. Dans votre domaine de recherche, il peut exister des paradigmes courants que vous êtes censé utiliser, ainsi que des controverses ou des débats auxquels vous devez être attentif. Vous devriez également adopter la terminologie et les bases technologiques de votre domaine pour mieux communiquer avec vos pairs. Cela s’applique à la fois à la conception de la recherche elle-même et à la manière dont vous rapportez et diffusez vos résultats.
Vous pouvez également avoir une audience sous la forme d’investisseurs, qu’il s’agisse de sociétés de capital-risque, d’organismes de financement gouvernementaux ou de particuliers. Si ce financement soutient actuellement votre recherche, indiquez clairement les résultats et les rapports auxquels vous vous êtes déjà engagé et dans quels délais, car vous devrez peut-être mettre en place une recherche pour répondre directement à ces exigences. Si vous concevez une recherche pour obtenir un financement futur, examinez les projets antérieurs que l’organisation ou l’individu a financés et réfléchissez au type de preuves qu’ils ont fournies. Par exemple, étaient-ils intéressés par des projets avec une preuve de concept en laboratoire terminée, ou des données sur l’adoption prévue par le grand public, ou des tests effectués dans des environnements réels imprévisibles? Connaître les réponses à ces questions vous aidera à encadrer votre propre recherche.
Entreprises peut également signifier un public pour votre travail, par exemple les entreprises qui utilisent l’automatisation à grande échelle dans des environnements industriels. Cette relation peut prendre la forme d’un contrat existant ou de ventes potentielles. Vous devez être très clair sur les facteurs qui seront les plus importants pour les personnes clés de cette organisation afin de pouvoir concentrer vos recherches sur la démonstration de la capacité dans ces domaines. Vous devez également identifier les formes de preuves qui seront les plus convaincantes pour ce public – recherchent-ils de grands essais de sécurité en laboratoire, ou des taux d’erreur humains-robots réels, ou un examen par des experts?
Consommateurs et/ou le grand public peuvent également constituer le public cible de votre recherche, en particulier si vous faites preuve d’efficacité dans un environnement réel ou si vous êtes intéressé à résoudre un problème particulier. Dans ce cas, vous devez réfléchir à ce que le consommateur cible trouverait persuasif et significatif, et incorporer ces éléments dans votre étude. Prenons l’exemple de la sécurité, qui est une préoccupation majeure pour le grand public. Une partie de votre recherche devrait donc porter sur la sécurité du robot dans des contextes d’utilisation courante, afin que vous soyez en mesure de formuler une conclusion fondée sur des preuves solides quant à la sécurité à la fin de votre projet.
13.4.3 Questions de recherche
La Méthode scientifique est le processus utilisé par les chercheurs pour créer une représentation précise du monde réel. En travaillant en collaboration, en nous appuyant sur des preuves et des théories et en les partageant, nous pouvons acquérir une compréhension de la façon dont les choses fonctionnent. La méthode scientifique implique la génération itérative de théories et d’hypothèses, la collecte de données et l’analyse de ces données pour tirer des conclusions, qui alimentent ensuite nos théories sur le monde, qui poursuivent ensuite le processus, affinant nos connaissances au fur et à mesure.
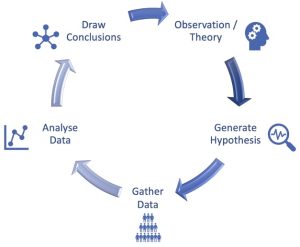
Figure 13-1 : Une représentation visuelle de la méthode scientifique utilisée pour mener des recherches.
Dans la recherche IHR, vous commencez généralement un projet de recherche avec une théorie sur la façon dont vous pensez qu’une interaction particulière entre un robot et un participant se déroulera. Cela peut être sur la base de recherches et de théories antérieures dans le domaine, ou sur la base d’observations que vous avez personnellement faites. Une théorie est un ensemble d’idées explicatives qui intègrent une variété de preuves. Les théories regroupent des faits en un principe général ou un ensemble de principes. Elles nous aident non seulement à expliquer le quoi, mais aussi le pourquoi des phénomènes observés. Les théories nous permettent également de faire des prédictions sur ce qui se passera dans une nouvelle situation. En tant que domaine de recherche multidisciplinaire, les théories en IHR pourraient être éclairées par de nombreuses idéologies parfois contradictoires. Quelques exemples sont la théorie de l’esprit de la psychologie, la théorie du contrôle perceptif de la cybernétique ou des idées plus spéculatives telles que l’effet Uncanny Valley en esthétique.
Dans le cadre d’une étude de recherche particulière, vous générerez une hypothèse, qui sera généralement basée sur une théorie. Une hypothèse est une déclaration spécifique sur la relation entre les variables de votre étude – ce à quoi vous vous attendez. Il est crucial que les hypothèses soient vérifiables – c’est-à-dire que les conclusions de votre étude soutiennent ou contredisent l’hypothèse. Lorsqu’une hypothèse (ou une théorie) n’est pas étayée par les données, on parle de falsification. L’hypothèse est la façon dont vous affinez votre théorie plus large pour évaluer un effet ou une relation particulière dans votre étude de recherche.
| Exemples de recherche : Théories et hypothèses
Sylax : Un projet universitaire de recherche en robotique
Tommy : Un robot conçu par une jeune entreprise pour être commercialisé
Coramand : Un produit robotique d’une entreprise technologique pour un déploiement industriel à grande échelle
|
| Ce que vous devez savoir avant de vous lancer dans un projet de recherche
Je mène cette étude de recherche parce que : ___________________________________________________________________ Le(s) public(s) cible(s) de ma recherche sont : ___________________________________________________________________ La ou les théories clés pertinentes à mon étude sont : ___________________________________________________________________ Mon hypothèse principale pour l’étude est la suivante : ___________________________________________________________________ |
En résumé, avant de commencer votre étude, tenez compte de votre motivation pour mener l’étude, de votre public cible et des théories pertinentes pour votre étude. Utilisez-les pour déterminer votre hypothèse. Rappelez-vous qu’elle doit être spécifique à votre étude et doit être également vérifiable. Prenons l’exemple de la prédiction selon laquelle les robots dotés de visages seront mieux acceptés par le grand public que les robots sans visage – il s’agit d’une théorie. En revanche, affirmer dans votre étude que le robot doté d’un visage obtiendra des scores de sympathie plus élevés que le même robot dont le visage est masqué est une hypothèse. L’hypothèse fait directement référence à ce que vous allez manipuler et mesurer dans votre étude, et nous l’explorerons plus en détail ci-dessous.
13.5 Décider de vos variables de recherche
13.5.1 Variables
Lors d’une recherche, l’une des principales tâches consiste à décider ce que vous allez manipuler et ce que vous allez mesurer. Cela dépend évidemment de votre question de recherche. Par exemple, si vous souhaitez étudier la sécurité perçue dans le cadre domestique, celle-ci sera mesurée de manière très différente par rapport à une question de recherche axée sur la sécurité opérationnelle dans un cadre industriel. L’évaluation de la sympathie d’un robot par de jeunes enfants utilisera une approche différente de la mesure de l’agentivité attribuée à un robot par un adulte.
Une variable est une caractéristique qui peut être mesurée ou modifiée. L’âge, la préférence d’objet, les conditions expérimentales, le temps de réaction et les performances sont tous des variables. Certaines de ces variables sont inhérentes à un individu et ne peuvent être attribuées (par exemple, l’âge), d’autres changent en fonction de la tâche (par exemple, la performance) et d’autres peuvent être manipulées par un chercheur (par exemple, l’exposition à différentes conditions). Décider quelles variables vous voulez mesurer/manipuler est l’un des problèmes clés de la conception de la recherche et dictera quelles sont les conclusions que vous serez en mesure de tirer.
Une distinction utile est entre les Variables indépendantes (VI) et les Variables dépendantes (VD).
- La VI est la variable qui, selon vous, a un effet sur les autres variables. Dans certaines études, la VI est manipulée (modifiée) par le chercheur. Dans la recherche en robotique, il s’agit souvent d’un aspect du système robotique, par exemple votre VI peut être de savoir si le robot a un visage anthropomorphe ou non.
- Dans une VI, vous avez souvent des conditions (aussi appelé niveaux ou groupes) – vous « faites des choses différentes » pour les différents groupes. Il peut y avoir un certain nombre de conditions. Il existe parfois des conditions expérimentales et de contrôle claires, telles que la condition expérimentale est le groupe recevant le traitement, et la condition de contrôle est le groupe de comparaison (ou groupe « habituel »). Par exemple, si votre VI est le type de visage robotique, vous pouvez avoir deux conditions – une dans laquelle les participants voient le visage du robot par défaut (condition de contrôle) et une dans laquelle ils voient une nouvelle version du visage (condition expérimentale).
- La VD est la variable qui est mesurée (observée) par le chercheur. Souvent, il y a plusieurs VD dans une seule étude – par exemple, vous voudrez peut-être mesurer les évaluations de sympathie, d’animéité et de sécurité des participants.
- Remarque : Dans certaines approches de recherche, telles que la recherche descriptive, toutes les variables sont mesurées simplement et le chercheur ne suppose pas qu’il y ait une relation causale entre elles. Dans ce cas, elles peuvent toutes être considérées comme des VD.
| Exemples de recherche : VI et VD
Sylax : Un projet universitaire de recherche en robotique
Tommy : Un robot conçu par une jeune entreprise pour être commercialisé
Coramand : Un produit robotique d’une entreprise technologique pour un déploiement industriel à grande échelle
|
13.5.2 Opérationnalisation
Maintenant que vous savez ce que vous voulez étudier et pourquoi, que vous avez identifié votre théorie et votre hypothèse clés, et que vous avez déterminé votre variable indépendante (VI) et votre variable dépendante (VD), vous êtes prêt à commencer, n’est-ce pas? Eh bien, pas tout à fait! La prochaine étape clé consiste à opérationnaliser vos variables – ce qui implique définir ce que vous manipulez et mesurez, et comment. Aux fins du projet de recherche que vous menez, vous décidez très précisément comment vos variables seront modifiées ou mesurées. Cela peut impliquer une question d’enquête ou un ensemble de questions combinées en une seule valeur, ou une mesure du temps de réaction ou de la performance d’une tâche.
Disons que votre VD représente la sécurité – à quel point les personnes se sentent en sécurité lorsqu’elles interagissent avec une conception robotique particulière. Il existe de nombreuses façons différentes de rendre opérationnelle cette variable, par exemple, vous pouvez utiliser une question d’enquête auto-déclarée (dans quelle mesure vous êtes-vous senti en sécurité lors de cette interaction? (5 Très sûr à 1 Pas sûr du tout), ou vous pouvez évaluer à quelle distance les participants se tiennent du robot (les personnes se tenant plus près indiquant un niveau de sécurité plus élevé), ou vous pouvez mesurer la fréquence cardiaque ou le niveau de cortisol des participants pour indiquer leur niveau de stress lors de l’interaction. Toutes ces différentes façons de rendre opérationnelle la notion de sécurité, et bien d’autres encore (!), pourraient être appropriées en fonction de votre « pourquoi », de votre question de recherche et de votre public cible. Cependant, l’opérationnalisation est souvent influencée par des considérations logistiques et contextuelles ainsi que par des approches théoriques plus profondes. Par exemple, quel équipement avez-vous? De quelle expertise disposez-vous et les autres chercheurs? De combien de temps disposez-vous pour collecter les données? Est-ce que les participants potentiellement concernés sont prêts et intéressés à être mesurés de cette manière?
La façon dont vous opérationnalisez votre variable aura des implications fondamentales sur les conclusions qui peuvent être tirées de votre étude. Il est important de garder à l’esprit que la manière dont vous opérationnalisez la variable a un impact direct sur les tests statistiques que vous pouvez effectuer lors de l’analyse (voir la discussion ultérieure). Par exemple, si vous utilisez une tâche de choix, une échelle oui/non, une échelle catégorielle ou un nombre continu, cela peut nécessiter des analyses statistiques différentes.
13.5.3 Compromis pertinence-sensibilité
Ce que nous recherchons dans une variable est une mesure suffisamment sensible pour montrer une différence qui vous intéresse (c’est-à-dire, ne mesurez pas quelque chose qui est peu susceptible de changer). Mais vous devez également faire attention à ne pas choisir une variable qui est tellement spécifique qu’elle n’est pas pertinente au-delà de l’étude pour d’autres contextes (c’est-à-dire, ne mesurez pas quelque chose qui n’a pas de sens dans le monde entier). C’est ce qu’on appelle le compromis pertinence-sensibilité. Cela peut s’avérer être un véritable problème dans les expériences en laboratoire, où l’accent est mis sur la recherche d’un moyen de mesurer la variable qui est facile dans cet environnement, plutôt que sur l’opérationnalisation de la variable d’une manière plus pertinente pour l’environnement réel.
| Exemples de compromis pertinence-sensibilité
Prenons comme exemple le cas de Tommy, le robot d’accompagnement destiné au grand public. Dans une expérience soigneusement contrôlée, vous pouvez demander aux participants s’ils aiment le robot sur une échelle de 1 à 100. Disons que vous avez ajouté de nouvelles fonctionnalités et que les scores de sympathie sont passés d’une moyenne de 50 à une moyenne de 60. Cela à l’air être grand! Mais cela signifie-t-il réellement que davantage de personnes achèteront le produit? Pas nécessairement. L’échelle d’attachement est suffisamment sensible pour prendre en compte les changements en fonction des améliorations que vous avez apportées, mais est-ce que ce changement de score pertinent si ce que vous voulez vraiment savoir si les personnes vont l’acheter ou non? |
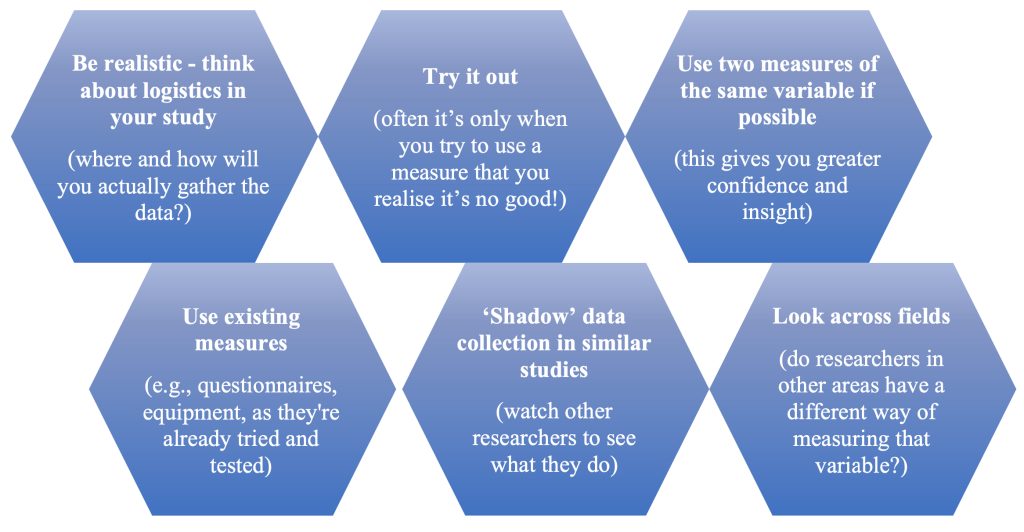
Figure 13-2 : Approches qui peuvent vous aider à décider comment opérationnaliser les variables.
13.5.4 Dessins de recherche
Il existe d’innombrables façons de mener des recherches et différentes façons de regrouper ces approches. Une catégorisation courante des modèles de recherche est la recherche descriptive, corrélationnelle, expérimentale, et les revues et méta-analyses.
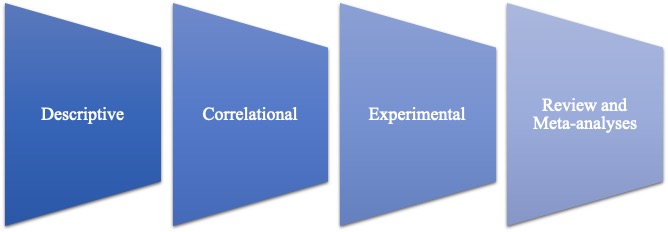
Figure 13-3 : Une catégorisation des différents types de modèles de recherche.
13.5.5 Recherche descriptive
Lorsque vous menez une recherche descriptive , vous n’êtes pas en train de manipuler les variables – vous observez plutôt le comportement naturel pour mesurer ce qui vous intéresse. Certaines de ces approches sont très flexibles, donc si des événements imprévus surviennent pendant votre recherche, ou si vous développez de nouvelles idées, vous pouvez modifier la façon dont vous collectez vos données pour en tirer parti. Quelques exemples de recherche descriptive sont observation (où vous enregistrez les comportements de vos participants sans interférer – par exemple, en examinant des séquences vidéo d’utilisation domestique d’un robot), recherche d’archives (en utilisant des données existantes – par exemple, en étudiant l’historique de recherche du navigateur Web), et évaluation du programme (par exemple, analyser les résultats d’un système robotique intégré dans un lieu de travail). Les Groupes de discussion sont également un moyen de mener une recherche descriptive dans laquelle vous vous asseyez avec de petits groupes de participants et leur demandez de donner leur avis et de décrire leurs comportements. Demander des informations descriptives à de grands groupes de participants se fait souvent à l’aide d’enquêtes. Dans le cas de l’exemple du robot Coramand utilisé ci-dessus, l’entreprise elle-même peut souhaiter mener une recherche descriptive sous forme de groupes de discussion, pour comprendre ce que ses employés pensent de l’intégration de robots dans l’usine, avant de s’engager à les mettre en œuvre.
Une méthode de recherche descriptive courante utilisée en robotique est les études de cas. Les études de cas sont une méthode de recherche descriptive couramment utilisée en robotique. Ces études sont utiles, car elles fournissent des informations très détaillées sur une expérience spécifique, ce qui permet d’explorer toutes les nuances de la situation, du comportement et de la cognition de cette personne. Elles sont aussi parfois la seule option, lorsque la situation ou l’expérience ou le contexte est si inhabituel que d’autres recherches ne peuvent pas être utilisées, comme discuté dans le chapitre 3 sur la Conception. Cependant, il est difficile de généraliser à partir d’études de cas (ce même modèle de comportement ou de résultats sera-t-il observé dans d’autres contextes ou individus?) et vous ne pouvez pas être sûr de ce qui a causé des changements dans le comportement de l’individu – ce n’est peut-être pas la variable sur laquelle vous vous êtes concentrés, mais il pourrait s’agir de quelque chose d’autre dans leur environnement ou qui leur est propre.
13.5.6 Recherche corrélationnelle
La Recherche corrélationnelle est une recherche qui demande s’il existe une relation entre deux variables ou plus, mais où les variables ne sont pas sous le contrôle direct du chercheur (pour des raisons logistiques ou d’éthique). Souvent une recherche basée sur des enquêtes tombe dans cette catégorie – bien qu’elle puisse être purement descriptive (voir ci-dessus), des enquêtes sont parfois utilisées pour déterminer si deux variables « vont ensemble », comme évaluer si l’âge est lié à la perception du degré de dangerosité des robots. Les enquêtes sont utiles lorsque vous souhaitez examiner des modèles naturels dans le monde et sont relativement faciles à mener. Elles vous permettent également de mesurer un grand nombre de variables en même temps. L’exemple de Tommy discuté ci-dessus, dans lequel les chercheurs voulaient connaître la relation entre l’exposition antérieure aux robots et l’attachement au produit robot, est un exemple de conception d’enquête; les chercheurs effectuent une analyse corrélationnelle pour déterminer si ces deux variables « vont ensemble ». Cependant, une recherche corrélationnelle comme celle-ci ne peut vous renseigner que sur la corrélation entre deux variables, et non sur le fait qu’une variable provoque des changements dans une autre variable. Pour cela, il est nécessaire de mener une expérience!
13.5.7 Recherche expérimentale
La Recherche expérimentale étudie l’effet d’une variable indépendante sur une variable dépendante. Ainsi, l’exemple du robot Sylax discuté ci-dessus, qui examinait l’effet du type de comportement (la VI : aléatoire ou délibérée) sur l’agentivité perçue (la VD) serait une expérience. Souvent, lorsque vous manipulez une VI, vous mesurez toute une gamme de VD (par exemple, la sympathie, l’animéité, la sécurité). Les expériences sont normalement effectuées dans des environnements de laboratoire hautement contrôlés, mais peuvent également être menées dans des environnements naturels – celles-ci sont connues sous le nom d’expériences de terrain.
Dans une expérience, vous voulez généralement savoir si une manipulation particulière (par exemple, ajouter un visage à un robot) a un effet. Imaginons que vous souhaitiez comparer une situation où vous effectuez cette manipulation à une autre où vous ne la faites pas. Il existe plusieurs méthodes pour procéder :
- Une condition de contrôle est un groupe où il n’y a pas de traitement ou de manipulation de la VI.
- Une condition placebo est un groupe qui reçoit ce qui ressemble au traitement/manipulation, mais qui ne l’est pas. Il s’agit d’un traitement « qui ressemble » sans le composant/ingrédient actif.
13.5.8 Conceptions inter-sujets et intra-sujets
Considérez la recherche Sylax discutée ci-dessus, dans laquelle un chercheur dispose d’une VI qui représente le type de comportement et mesure l’agentivité perçue. Dans cette étude, le chercheur a mis en place deux conditions – une où les participants sont exposés à un comportement aléatoire (condition de contrôle) et une autre où ils sont exposés à un comportement délibéré (condition expérimentale). Le chercheur a alors le choix :
- Il peut recruter 40 participants et en affecter 20 à la condition de contrôle (comportement aléatoire) et 20 à la condition expérimentale (comportement intentionnel), et comparer les scores des deux groupes.
- Il peut recruter 20 participants et demander à ces participants de remplir à la fois les conditions de contrôle et expérimentales à des moments différents, et de comparer les scores des participants sur les deux conditions.
Dans l’un de ces cas, différentes personnes éprouvent chacune des différentes conditions; dans l’autre, les mêmes personnes remplissent les deux conditions. Ces deux options sont légitimes dans des circonstances particulières, mais elles présentent chacune des avantages et des inconvénients éventuels dont vous devez être conscient lors de la conception de votre étude.
Dans une conception intra-sujets les participants sont affectés à toutes les conditions de la VI, de sorte que la manipulation expérimentale a lieu intra-sujets. Si vous aviez trois conditions dans votre VI, par exemple, les participants remplissent les trois conditions (ils pourraient les faire séquentiellement au cours de la même session de test ou participer à votre étude durant trois jours différents). Vous comparez ensuite les scores des mêmes participants dans les trois conditions différentes.
Dans une conception inter-sujets les participants sont affectés à une seule condition de la VI, de sorte que la manipulation expérimentale a lieu entre les sujets. Si vous aviez trois conditions pour votre VI, vous auriez alors trois groupes de participants, chacun remplissant une condition différente (chaque individu ne participant à qu’une seule condition). Vous compareriez ensuite les scores des trois différents groupes de personnes.
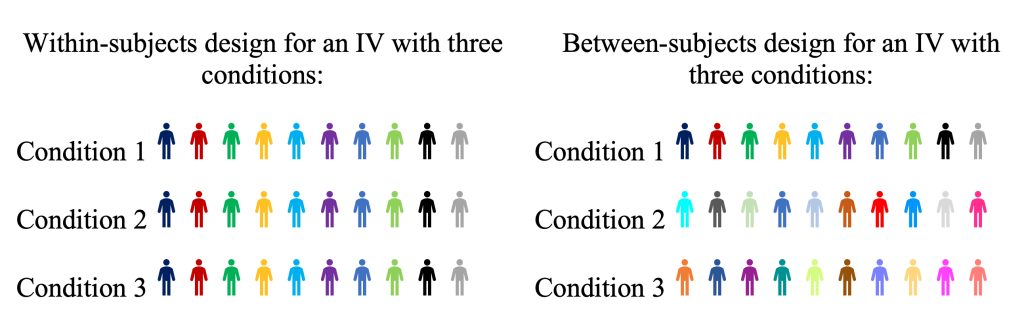
Figure 13-4 : Illustration des différences entre les conceptions de recherche intra-sujets et inter-sujets, avec différents individus représentés par des symboles de couleurs différentes.
Les conceptions intra-sujets et inter-sujets peuvent être appropriées selon la situation. Souvent, la nature de l’étude déterminera cela pour vous. Par exemple, si vous voulez tester s’il y a une différence d’apprentissage entre deux interfaces, vous pourriez ne pas pouvoir utiliser une conception intra-sujets, car l’apprentissage réalisé sur une interface pourrait être transféré à l’autre. Les performances sur la deuxième interface pourraient être meilleures que sur la première, indépendamment de l’interface elle-même. Ainsi, si l’exposition à une condition peut potentiellement affecter les réponses dans d’autres conditions, il peut ne pas être approprié d’utiliser une conception intra-sujets. De même, si les participants ne sont disponibles que pour une session de test unique et que les conditions de participation impliquent une tâche de haute intensité, les participants peuvent être trop fatigués pour remplir plus d’une condition. Si vous utilisez une conception intra-sujets, une façon de résoudre les problèmes d’ordre potentiels consiste à utiliser un système de contrebalancement, qui consiste à présenter les conditions dans un ordre alterné (ou aléatoire) aux participants, de sorte que la moitié des participants expérimente la condition 1 en premier, et l’autre moitié la condition 2 (et etc. le cas échéant s’il existe des conditions supplémentaires).
L’organisation d’éléments tels que ceux-ci et les contraintes de temps potentielles sur la participation des participants signifient que les conceptions intra-sujets peuvent être plus difficiles sur le plan logistique que les conceptions inter-sujets. Cependant, elles sont statistiquement plus « puissantes » (voir la discussion ultérieure sur la puissance) en ce que cette conception réduit la variance aléatoire dans les données collectées et signifie que vous êtes susceptible de trouver un effet significatif s’il y en a un plutôt que d’utiliser des conceptions inter-sujets. Cependant, elles ont une plus grande « puissance » statistique (voir la discussion ultérieure sur la puissance) en ce sens qu’elles réduisent la variance aléatoire dans les données collectées, ce qui signifie que vous êtes plus susceptible de trouver un effet significatif s’il y en a un, plutôt que si vous utilisiez des conceptions inter-sujets.
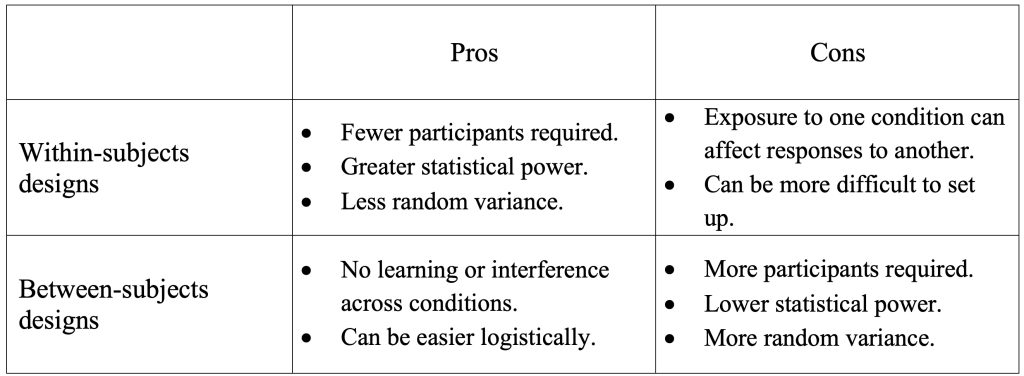
Figure 13-5 : Avantages et inconvénients des conceptions de recherche intra-sujets et inter-sujets.
13.5.9 Affectation aléatoire
Si vous menez une étude dans laquelle les participants sont affectés à une seule condition d’une VI (c’est-à-dire une conception inter-sujets), vous devez décider comment affecter les participants à une condition particulière. Autrement dit, lorsqu’un participant franchit la porte, à quelle condition sera-t-il exposé? Vous pouvez décider en fonction de toute une série de facteurs – par exemple l’ordre d’arrivée en alternance, le nom de famille, le jour de la semaine. Dans la recherche en robotique, le choix de la conception de l’étude est souvent dicté par des facteurs techniques tels que le temps nécessaire pour mettre en place une condition expérimentale. Par exemple, si cela prend beaucoup de temps, les six premières semaines de collecte de données pourraient impliquer que les participants soient affectés à la condition A, suivies des six semaines suivantes à la condition B.
Cependant, si possible, veuillez utiliser une affectation aléatoire pour affecter les participants aux conditions. Autrement dit, assurez-vous que les participants sont affectés au hasard à l’une ou l’autre des conditions (ou à toutes les conditions, s’il y en a plus de deux). Cette affectation peut être réalisée en utilisant un générateur de nombres aléatoires ou un procédé similaire (ou encore de manière plus traditionnelle, en choisissant un numéro dans un chapeau). L’affectation aléatoire est importante parce qu’elle exclut la possibilité de différences systématiques entre les groupes. Par exemple, disons que vous soumettez les 10 premiers participants qui participent à votre étude dans une condition de « robot sans visage », et les 10 seconds participants dans une condition de « robot avec visage ». Vous demandez aux deux groupes de participants à quel point ils se sentent en sécurité sur une échelle de 7 points allant de « pas du tout en sécurité » à « complètement en sécurité ». Le souci avec méthode est que des différences préexistantes entre les groupes pourraient bien exister – par exemple, les participants qui s’inscrivent plus tôt pour une expérience peuvent être plus enthousiastes, plus consciencieux, avoir des opinions plus positives envers les robots, et être plus susceptibles d’être des femmes. Vous pouvez donc vous retrouver avec des différences significatives entre les groupes sur la base des différences existantes, et non sur l’effet de la VI que vous testez réellement. En utilisant l’affectation aléatoire à des groupes, vous réduisez les biais systématiques entre les groupes, ce qui renforce votre capacité à affirmer avec confiance que la variable indépendante est la cause des changements observés dans votre VD. Donc, si vous avez vraiment besoin de démontrer un effet occasionnel, vous devez utiliser l’affectation aléatoire. Si l’affectation aléatoire n’est pas possible, essayez plutôt de « faire correspondre » les participants dans chaque condition autant que possible – en visant un équilibre similaire en termes de sexe, d’âge, d’ethnie, etc. Cependant, sans l’affectation aléatoire, vous ne pouvez pas affirmer avec certitude que votre VI est la cause des changements dans la VD.
| Affectation aléatoire et non aléatoire
Coramand : Les chercheurs examinent l’effet du type de mouvement (VI : deux conditions – fluide et robotique) sur la sécurité perçue. En raison de contraintes techniques, ils exposent d’abord 10 participants (personnes du bureau) à la condition de mouvement fluide, puis une semaine plus tard exposent 10 participants différents à la condition de mouvement robotique. Ils comparent la sécurité perçue telle que rapportée par les participants de chaque groupe. Chaque participant n’était donc pas affecté au hasard aux différentes conditions. Les chercheurs doivent prendre en compte que les disparités existantes entre les deux groupes de participants pourraient avoir contribué aux différences observées dans les réponses entre les groupes (par exemple, les personnes qui ont accepté de participer en premier pourraient être plus investies dans le projet et avoir des attentes de sécurité moins élevées que celles qui ont accepté plus tard). Tommy : Les chercheurs veulent savoir si le robot aux capacités améliorées (VI : deux conditions – originale et améliorée) produit plus d’attachement chez les participants (VD). Lorsque chaque participant reçoit un robot, il est affecté au hasard via un algorithme pour recevoir soit un produit avec les capacités d’origine, soit un produit avec des capacités améliorées. Lorsque les chercheurs comparent les évaluations de l’attachement entre les deux groupes de participants, ils peuvent en déduire que les différences qu’ils observent ne sont pas attribuables aux disparités initiales entre les groupes. |
13.5.10 Examens et méta-analyses
Certaines recherches ne collectent pas de nouvelles données, mais « rassemblent » toutes les données de recherches publiées sur un sujet particulier dans un seul article et les résument – elles sont appelées articles de revue. Les articles de revue sont considérés comme des sources secondaires, car aucune nouvelle donnée brute n’est collectée. Les articles de revue sont incroyablement utiles, car ils rassemblent les recherches clés qui ont étudié une question particulière. Certains articles de revue sont désignés comme des revues systématiques s’ils ont recours à des méthodes systématiques pour examiner la littérature – ils exposent les termes de recherche qu’ils ont utilisés, les bases de données consultées et définissent des critères d’éligibilité préalablement spécifiés pour les études à inclure dans la revue. Les revues systématiques vous donnent une évaluation rigoureuse des résultats sur un sujet de participant, de sorte qu’elles constituent la meilleure preuve disponible pour répondre à une question de recherche particulière. Si vous travaillez pour commercialiser un robot auprès d’une organisation, vous pouvez réaliser une revue systématique des études de sécurité disponibles pour établir et communiquer clairement au client potentiel les preuves actuelles de la sécurité dans ce contexte. Ou vous pouvez effectuer une revue systématique avant de commencer un projet de recherche, car s’il existe déjà suffisamment de preuves, vous n’aurez peut-être pas besoin de mener l’étude! Cependant, gardez à l’esprit que les revues systématiques peuvent être d’une portée trop limitée, de sorte qu’elles peuvent ne pas répondre à la question particulière qui vous intéresse et qu’elles ne vous donnent parfois pas une « vue d’ensemble » de ce qui se passe dans ce domaine.
Les méta-analyses sont généralement des revues systématiques dans lesquelles l’auteur analyse également statistiquement les données qu’il a trouvées dans les études qu’il a passées en revue. De cette façon, ils peuvent générer de nouvelles données qui résument numériquement les résultats. Les méta-analyses permettent une évaluation objective des preuves dans un domaine, mais si la sélection initiale des études est biaisée, les résultats de la méta-analyse peuvent être impactés.
13.5.11 Quelle est la meilleure conception de recherche?
Une théorie peut être explorée à l’aide d’un large éventail de conceptions – une conception n’est pas « meilleure » qu’une autre, elles fournissent simplement différentes façons d’examiner la théorie. Différentes conceptions vous donneront également différents types d’informations et vous permettront de tirer des conclusions différentes! Assurez-vous donc d’avoir une idée claire de votre motivation, de votre public cible et de votre question de recherche avant de concevoir votre étude.
| Comment peut-on utiliser différents modèles de recherche pour examiner une question de recherche.
Considérons l’exemple de Sylax, un projet de recherche en robotique universitaire qui se penche sur l’impact de facteurs tels que le comportement et l’apparence du robot sur l’agentivité perçue par les personnes. Vous pouvez utiliser un large éventail de modèles de recherche pour étudier cette question, en fonction des facteurs particuliers qui vous intéressent. Conception descriptive : Si vous commencez tout juste à examiner cette question de recherche et que vous cherchez à mieux comprendre les interactions humain-robot, vous pourriez inviter un seul participant et lui demander d’interagir avec le robot sur une période prolongée, tout en enregistrant cette interaction en vidéo. Ensuite, vous pourriez vous asseoir avec le participant et regarder ensemble la vidéo en examinant et discutant de toutes les interactions, pour comprendre ses pensées et ses émotions pendant l’interaction, en vous concentrant particulièrement sur les aspects qui vous intéressent (tels que l’apparence et l’agentivité). Conception de l’enquête : Vous pouvez recruter un grand nombre de personnes pour interagir avec le robot, puis après l’interaction, leur faire remplir une enquête sur ce qu’ils ont remarqué sur l’apparence du robot et sur la note qu’ils ont attribuée à l’agentivité perçue. Conception expérimentale : Une expérience peut être menée dans laquelle un groupe de participants interagit avec un robot sans visage, tandis que l’autre groupe interagit avec un robot à visage humanoïde, puis les notes d’agentivité perçue par chaque groupe peuvent être comparées. Revoir la conception : Vous pouvez consulter des recherches antérieures qui ont déjà exploré ce sujet. Si vous vouliez vous concentrer sur l’effet de l’apparence faciale sur l’agentivité perçue, par exemple, vous pourriez identifier toutes les études publiées au cours des 30 dernières années qui impliquaient de présenter différents types de visages aux participants et de mesurer l’agentivité, et résumer leurs conclusions pour arriver à une conclusion sur la preuve que les visages affectent l’agentivité. |
13.6 Échantillonage, fiabilité et validité
13.6.1 Échantillonnage
Aux fins de généralisation, vous devez faire de votre mieux pour vous assurer que le groupe de personnes dans votre étude – votre échantillon – est un échantillon représentatif de la population à laquelle vous souhaitez appliquer vos résultats – la population. Autrement dit, vous obtenez vos données à partir d’un échantillon qui a les mêmes caractéristiques que la population (par exemple, même répartition par sexe, même répartition par âge, même répartition ethnique). Si l’échantillon n’est pas représentatif de cette manière, cela peut entraîner de graves erreurs lorsque vous essayez d’appliquer vos résultats à la population. Par exemple, si vous utilisez des étudiants universitaires comme échantillon lors du test d’une interface utilisateur particulière, vous constaterez peut-être que lorsque vous déployez votre produit auprès de la population générale, les utilisateurs plus âgés ou plus jeunes que votre échantillon peuvent interagir très différemment avec l’interface.
Il existe deux grands types d’approches d’échantillonnage, appelées échantillonnage probabiliste et échantillonnage non probabiliste. L’échantillonnage probabiliste implique la sélection de membres de la population cible de manière à ce que chaque membre de la population ait une probabilité déterminée d’être sélectionné. Par exemple, une liste de tous les membres de la population peut être obtenue et chaque 10e personne sur la liste peut être choisie pour être contactée. Lorsque vous utilisez un échantillonnage non probabiliste, il n’y a pas de probabilité identifiable que chaque membre de la population soit inclus dans l’échantillon. Un exemple courant d’échantillonnage non probabiliste est échantillonnage de commodité, où il vous suffit de sélectionner votre échantillon parmi ceux qui sont disponibles autour de vous! Échantillonnage intentionnel est un autre type d’échantillonnage non probabiliste, où vous recrutez délibérément des personnes qui répondent à une certaine exigence – comme interroger des personnes âgées si c’est à qui le robot est destiné, ou recruter des ouvriers d’usine si le robot est un produit industriel.
Il est possible d’utiliser un échantillonnage non probabiliste tel que l’échantillonnage de commodité ou intentionnel, à condition que l’échantillon obtenu soit représentatif de la population pour les variables d’intérêt. Toutefois, il est important de noter que plus l’échantillon est grand, plus il est susceptible de refléter la population dans son ensemble, permettant ainsi une généralisation plus précise à la population. MAIS s’il y a un biais systématique dans votre échantillonnage, vous allez faire des inférences incorrectes avec plus de confiance… Par exemple, de nombreux robots conçus dans les universités ou dans les jeunes entreprises ne sont testés que par échantillonnage pratique avec des étudiants ou d’autres personnes impliquées dans l’entreprise. Cela signifie souvent que les participants sont seulement des personnes jeunes, déjà intéressées et bien informées sur les robots. Les résultats des études qui utilisent des échantillons comme ceux-ci ne s’appliqueront pas nécessairement au grand public! Gardez également à l’esprit que la taille de l’échantillon sera réduite en cas de non-réponse de sorte que les personnes impliquées abandonnent l’étude ou oublient de saisir des données.
13.6.2 Fiabilité
La fiabilité repose sur notre capacité de reproduire des résultats de manière cohérente et répétée, ce qui exclut l’idée d’une découverte aléatoire. Par exemple, si vous trouvez que les personnes réagissent plus positivement à un robot avec des caractéristiques enfantines qu’à un robot avec des caractéristiques adultes, cette conclusion est fiable si d’autres chercheurs trouvent systématiquement le même schéma. Vous pouvez considérer la fiabilité comme étant similaire à la cohérence. Cependant, juste parce qu’un effet ou un test est fiable ne veut pas dire qu’il est valide.
13.6.3 Validité
La validité est lorsque nous sommes convaincus que les résultats montrent ce que nous pensons qu’ils montrent. Il existe quatre principaux types de validité : la validité conceptuelle, la validité externe, la validité interne et la validité écologique.
La validité conceptuelle demande si nous avons mesuré ce que nous essayions de mesurer. Cela s’avère être plus complexe qu’il n’y paraissait à première vue! Souvent, les personnes n’interprètent pas la tâche ou ne remettent pas en question la façon dont vous avez l’intention, ou d’autres facteurs affectent la façon dont ils réagissent. Par exemple, souvent, lorsqu’on les interroge sur la facilité d’utilisation d’un robot, les réponses des personnes reflètent plutôt leurs jugements sur la sécurité.
La validité externe demande à quel point nous pouvons généraliser ce que nous avons trouvé dans notre étude à d’autres époques, populations et lieux. Imaginons que vous conduisiez une enquête sur les attitudes envers les jeux impliquant un robot, en ayant comme échantillon des étudiants de premier cycle canadiens. Les résultats seront-ils les mêmes si vous utilisez un échantillon d’une maison de retraite? Étudiants de premier cycle de la Chine? Dans 10 ans?
La validité interne demande si le résultat reflète la VI que nous avons manipulée. Est-ce que la variable qui nous préoccupe a causé le résultat observé? Supposons que vous meniez une étude dans laquelle vous souhaitez examiner l’effet du travail en équipe sur les performances. Vous demandez donc à certains participants d’accomplir une tâche difficile par eux-mêmes et à d’autres de l’accomplir avec d’autres personnes. Puis-je conclure que les performances inférieures dans le groupe de travail d’équipe sont dues au fait que le travail d’équipe en soi réduit les performances? Il est possible que ce ne soit pas le cas – le résultat pourrait être attribuable à des facteurs tels que l’embarras, les distances dans l’espace personnel, ou encore la charge cognitive, plutôt qu’à l’effet de l’équipe de travail en soi.
La validité écologique demande dans quelle mesure le résultat de l’étude s’applique aux paramètres du monde réel – dans quelle mesure ce résultat est valable dans le monde réel? Par exemple, si vous testez la façon dont les personnes utilisent un nouveau type de technologie en laboratoire, l’utiliseront-elles réellement de cette façon à la maison? Dans le bus? Au travail? Remarque : Cette méthode est différente de la validité externe, qui consiste à généraliser à d’autres populations/lieux.
13.6.4 Les éventualités où la validité peut être compromise.
Comme nous en avons parlé plus haut, un biais systématique dans votre échantillonnage peut affecter la validité externe. Si seuls certains types de personnes répondent à un questionnaire ou participent à une étude, cela limite à qui les résultats s’appliquent. Il est notoirement difficile de recruter des personnes d’âge moyen dans les études, par exemple, car elles sont occupées par de jeunes enfants et des emplois à temps plein. S’il s’agit de la personne qui va acheter votre produit, vous devez vous assurer que votre échantillon inclut ce groupe.
Mortalité – lorsque les personnes abandonnent une étude – cela peut également affecter la validité externe. Si, par exemple, l’étude requiert une heure de participation par jour, les individus ayant des contraintes de temps pourraient décider d’abandonner l’étude. En conséquence, les résultats obtenus ne pourront s’appliquer qu’aux personnes ayant une disponibilité similaire à celle des participants restants. Si vous menez une expérience et que plus de personnes dans une condition abandonnent que dans l’autre, cela peut également affecter la validité interne. Cela devient particulièrement problématique lors de la réalisation d’études longitudinales, qui s’étendent sur une longue période. Dans de tels cas, il est possible de constater un décrochage différentiel, où les participants sont plus susceptibles d’abandonner l’étude s’ils se trouvent dans une condition particulière plutôt que dans une autre. La réactivité désigne une situation où certains éléments de l’étude en question font en sorte que seules certaines personnes répondent ou affectent la manière dont les autres répondent. Donc, si vous annoncez votre étude comme « Venez jouer avec des robots! », vous n’obtiendrez que des personnes qui sont déjà positivement disposées à interagir avec un robot, excluant ainsi une grande partie de la société.
Vous devez également garder à l’esprit que la désirabilité sociale peut affecter la façon dont les personnes réagissent dans une étude, car les personnes ont tendance à se comporter en fonction de ce qu’ils pensent être bon pour les autres. Par exemple, les personnes ont tendance à sur-déclarer leur consommation de légumes et à sous-déclarer le nombre d’heures de télévision qu’ils regardent! Les personnes modifient également leurs réponses en fonction d’indices de recherche qui suggèrent comment ils devraient répondre – connu sous le nom de caractéristiques de la demande. Prenons l’exemple où le chercheur pose à plusieurs reprises la question à un participant s’il a apprécié la façon dont les yeux du robot ont bougé pour le suivre. Dans ce cas, le participant aura tendance à fournir davantage d’informations sur cet aspect (et de manière plus positive), même si d’autres aspects du robot ont été plus intéressants pour lui. Parfois, ils peuvent même inconsciemment modifier leurs réponses pour correspondre à ce qu’ils pensent que le chercheur veut. Vous devez également être conscient que souvent les personnes changent de comportement, tout simplement parce qu’elles sont surveillées! Ceci correspond à ce qu’on nomme l’effet observateur (par exemple, si vous saviez que votre consommation de sucre était surveillée, seriez-vous moins enclin à en consommer?).
Les effets du test correspondent à la situation où les résultats d’un test antérieur ont une influence sur le test qui suit. Si un écart est observé entre les résultats du pré-test et du post-test, cela peut être dû à des effets de pratique (c’est-à-dire que les participants ont tendance à s’améliorer sur une tâche s’ils la répètent) ou effets de fatigue (par exemple, est-ce que les participants resteront concentrés durant une session de test de deux heures?). Les effets de maturation sont liés à des changements qui se produisent simplement du fait que nous effectuons des mesures à différents moments dans le temps. Par exemple, si vous mesurez comment un enfant atteint d’une maladie de longue durée interagit avec un robot au fil du temps, les effets simples du vieillissement de l’enfant sont susceptibles d’influencer les résultats. Des changements dans la société peuvent également survenir au cours d’une étude, ce qui peut entraîner des effets historiques (par exemple, 9-11, COVID-19, opinions sociales sur la technologie). Vous devez veiller à ce que les modifications des données dues à ces facteurs ne soient pas mal interprétées.
Le fait de confondre est une autre menace pour la validité interne et reflète les changements de votre VD qui sont dus à une autre variable et non PAS à votre VI. Imaginez que vous introduisiez un robot d’apprentissage dans une école dans le but d’améliorer les compétences mathématiques des élèves. Vous comparez les compétences en mathématiques dans les salles de classe sans robot à celles avec le robot. Cependant, lors de l’ajout du robot dans la salle de classe, cela implique le changement, l’excitation, le nouveau personnel, etc. Toute amélioration des « compétences mathématiques » pourrait être due à l’un de ces facteurs, plutôt qu’au robot lui-même.
13.6.5 Façons de résoudre les problèmes de validité
La section ci-dessus, avec tous les nombreux problèmes potentiels, pourrait donner l’impression qu’il est impossible de concevoir une étude « parfaite »! Bien qu’une étude individuelle ne puisse jamais éviter absolument toutes les sources potentielles de biais, il existe des mesures simples que vous pouvez prendre pour résoudre bon nombre de ces problèmes.
Pour pallier à la réactivité, aux caractéristiques de la demande et à l’effet observateur, on peut utiliser des mesures discrètes, qui consistent à observer des comportements qui ne sont pas apparents pour la personne observée. Par exemple, l’utilisation de miroirs sans tain, la mesure de facteurs dont les personnes ne sont généralement pas conscientes (comme la distance à laquelle elles se tiennent d’une interface de robot ou la fréquence à laquelle ils la touchent) ou l’utilisation d’autres méthodes, telles que les documents d’archives, qui sont des données qui ont été collectées dans un but différent. Vous pouvez contribuer à réduire les caractéristiques de la demande et la réactivité en masquant le véritable objectif d’une expérience. Vous pouvez utiliser la déception, où vous mentez aux participants sur le but d’une expérience, ou vous pouvez utiliser la dissimulation pour éviter de leur dire toute la vérité (mais faites attention à l’éthique! Voir ci-dessous). L’utilisation de l’insu est également très utile pour traiter une gamme de biais potentiels. L’insu se réfère à la situation où les personnes clés impliquées dans l’étude ne sont pas au courant des informations qui pourraient influencer leurs réponses. Dans les études à simple insu , les participants ne savent pas dans quel groupe de traitement (niveau de la VI) ils se trouvent. Dans les études à double insu, les participants et les chercheurs ne savent pas dans quel groupe de traitement se trouvent les participants.
Concentration sur les laboratoires vivants
|
13.7 Éthique
13.7.1 L’éthique et les comités d’éthique
Tout au long de ce chapitre, nous avons parlé de la conception et de l’évaluation des études – recrutement, échantillonnage, randomisation, etc., cependant il est également important de tenir compte des principes en matière d’éthique dans la conception de la recherche. Bien que la plupart des études robotiques en laboratoire soient relativement bénignes, il est toujours essentiel de pouvoir identifier et résoudre les problèmes liés à l’éthique et de démontrer à un comité d’éthique de la recherche ou à un comité d’examen institutionnel que votre étude est appropriée. Cela s’ajoute à la prise de conscience des implications plus larges des considérations, liées à l’éthique, dans la conception de robots abordée au chapitre 16 et de la sécurité du déploiement de robots abordé au chapitre 14.
| Problèmes courants liés à l’éthique dans les études sur les utilisateurs de robotique
Alors, quels sont certains des problèmes typiques liés à l’éthique auxquels vous pourriez être confronté lorsque vous menez une recherche sur l’interaction humain-robot?
|
Il existe des réglementations qui régissent les recherches qui peuvent être menées, généralement au niveau institutionnel, national et international, vous devez donc les consulter en fonction de l’endroit où vous vous trouvez. De plus, la Déclaration d’Helsinki de l’Association médicale mondiale (Principes éthiques pour la recherche médicale impliquant des sujets humains) s’applique à toute recherche que vous effectuez et dans laquelle vous recrutez des participants.
Le processus d’évaluation de l’éthique est une procédure formelle dans laquelle vous rédigez une déclaration comprenant des détails sur le projet de recherche et traitant de toute préoccupation liée à l’éthique, qui est ensuite soumise à un comité d’éthique de la recherche pour approbation. Le comité approuvera, rejettera ou demandera des modifications à l’étude ou de fournir plus d’informations avant l’approbation. Il est courant que de nombreux chercheurs perçoivent la demande d’approbation éthique comme une simple formalité logistique, cependant, les comités d’éthique ont parfois la capacité de mettre en lumière des problèmes éthiques concrets que le chercheur n’a pas envisagés. Les comités d’éthique sont généralement composés de chercheurs expérimentés, d’experts juridiques et de profanes. Chacun de ces groupes peut donner un aperçu de ces perspectives auxquelles vous n’avez peut-être pas pensé, qui nécessitent des changements dans votre projet.
13.7.2 Principes éthiques en recherche
Les principes éthiques peuvent être appréhendés de diverses manières, mais tous sont basés sur l’idée centrale selon laquelle il est primordial de témoigner du respect envers les individus participant à l’étude. Cela implique que vous preniez en considération leurs expériences et que vous preniez toutes les précautions nécessaires pour garantir leur consentement libre et éclairé ainsi que leur protection contre tout type de préjudice. Certains des principes clés à garder à l’esprit sont d’utiliser le consentement éclairé, de minimiser les risques, d’assurer la confidentialité et de fournir un débreffage.
13.7.2.1 Consentement éclairé
Les personnes devraient participer à votre étude sur une base de consentement éclairé. Cela signifie que vous leur fournissez toutes les informations pertinentes sur l’étude (y compris les risques potentiels), qu’elles lisent et comprennent ces informations et qu’elles ne subissent aucune pression pour participer à l’étude. Vous devez vous assurer que vos participants sont en mesure de donner leur consentement. Les enfants ou les personnes souffrant de troubles cognitifs (tels que la démence) nécessitent des vérifications supplémentaires, ce qui implique habituellement l’obtention du consentement éclairé tant du tuteur légal que de la personne elle-même. Vous devez également fournir des informations de manière à ce que ces personnes comprennent ce que vous dites (c’est-à-dire sans termes techniques ou jargon). Les participants doivent également être libres d’interrompre l’étude à tout moment. Cela signifie qu’ils peuvent se retirer de l’étude, sans aucune pénalité, et n’ont pas à fournir de raison pour le faire.
13.7.2.2 Minimiser les risques
Lors de la conception de votre recherche (et de la rédaction de votre demande d’éthique), vous devrez clarifier soigneusement les avantages et les risques liés à votre recherche. Soyez explicite en ce qui concerne les avantages : qu’est-ce que cette étude particulière nous apprendra de nouveau? Qui bénéficiera de ce que vous apprendrez de l’étude? Y aura-t-il une valeur sociale plus large? Les participants en retireront-ils des avantages? N’oubliez pas que tout dépend de la conception efficace de votre étude dès le départ, de manière à ce qu’elle vous fournisse des données précises sur ce que vous essayez d’évaluer.
Vous devez ensuite peser ces avantages par rapport aux risques. Un des risques les plus courants est le stress. Essayez de minimiser le stress non désiré ou inutile, et rappelez-vous que ce qui ne vous stresse pas pourrait l’être pour les participants! Il convient donc de réfléchir à toutes les façons de réduire le stress pour les participants. Si vous utilisez une déception – en donnant aux participants des informations fausses – il s’agit d’une source potentielle de risque, car cela viole le consentement éclairé et peut causer des dommages. Il est recommandé de n’utiliser la déception que si c’est nécessaire, et dans ce cas, vous devez prévoir un temps de débreffage (voir ci-dessous) pour informer le participant de cette déception et de la raison pour laquelle elle a été utilisée. Bien entendu, entreprendre quelque chose qui est considéré comme « invasif » comporte des risques! La recherche considérée comme invasive est celle qui altère les participants, tels que l’administration de médicaments, la mise en place d’un dispositif d’enregistrement à l’intérieur du corps d’une personne ou encore l’exposition à une situation où elle pourrait être potentiellement blessée ou touchée physiquement. Vous devez vous assurer que ce que vous faites est absolument nécessaire (l’étude n’atteindra pas ses objectifs sans une bonne recherche), que vous avez minimisé tout risque pendant l’étude, et supprimé tout effet négatif à long terme.
13.7.2.3 Confidentialité
Les participants fournissent souvent des informations sensibles pendant une étude et il est de votre responsabilité de maintenir ces informations confidentielles. Rappelez-vous également que les informations que vous pourriez considérer personnellement non sensibles (par exemple, le poids, la performance à une tâche) peuvent être considérées comme sensibles pour d’autres personnes. Il existe différentes façons d’assurer la confidentialité. La plus simple est de s’assurer que les participants restent anonymes – que les données qu’ils fournissent ne soient pas identifiables. Par exemple, utiliser un numéro d’identification de participant plutôt que des noms est une bonne pratique. Si vous effectuez une étude de cas, vous pouvez choisir de vous référer à cette personne par ses initiales ou un pseudonyme plutôt que par son nom. Si vous utilisez un enregistrement audio ou vidéo, vous devez spécifiquement demander l’autorisation des participants à cet effet sur le formulaire de consentement. Le stockage et la protection des données doivent également être pris en compte : où sont stockées les données? Aucune personne qui ne fait pas partie du projet, ne doit avoir accès aux données. Assurez-vous que les périphériques de stockage sont protégés de manière appropriée et sécurisée.
13.7.2.4 Débreffage
Le débreffage permet aux participants qui ont pris part à votre étude de comprendre exactement de quoi il s’agissait et ce qui s’est passé pendant l’étude. En informant les participants de manière honnête sur ce qui s’est passé pendant l’étude et sur les raisons des éventuelles déceptions, vous pouvez neutraliser tout mécontentement et minimiser les dommages potentiels. Vous devez également les encourager à poser des questions sur l’étude et vous devez y répondre.
| Le paradigme du magicien d’Oz
Lorsqu’ils mènent des études sur les utilisateurs, les chercheurs peuvent parfois avoir besoin que les robots participants présentent des capacités supérieures à leurs capacités techniques actuelles (en raison de la technologie actuelle ou de la disponibilité des ressources). Dans de tels cas, une technique couramment utilisée en interaction humain-robot (IHR) consiste à améliorer les compétences manquantes en intégrant un « assistant » humain. Prenons le cas de Tommy (voir ci-dessus) comme exemple. Si nous voulions étudier l’impact sur l’attachement au robot participant en comparant une version de Tommy qui utilise la communication verbale à une version qui utilise uniquement des signaux non verbaux, il pourrait être difficile de mettre en place un système de traitement du langage naturel fluide qui puisse imiter de manière appropriée la compétence humaine. Dans une telle situation, un complice (un autre chercheur) pourrait être placé derrière un rideau pour converser avec le participant à la recherche, à travers le robot, donnant l’illusion que le participant converse avec le robot. Le concept vient du roman fantastique classique « Le merveilleux magicien d’Oz » de L. Frank Baum. Tout en aidant les chercheurs à contourner les difficultés techniques dans la conduite d’études sur les utilisateurs, il convient de souligner que la pratique a des implications éthiques et sociales. Éthique, en ce sens que vous trompez potentiellement un participant à la recherche en lui faisant croire que l’interaction est purement avec un robot. Socialement, lorsque de telles recherches sont présentées dans les médias au sens large, il existe un risque de déformer l’état actuel de la technologie, conduisant à une fausse compréhension des capacités des robots. Cela a des implications pour le financement de la recherche et la formation d’attentes ou de craintes exagérées envers les robots dans la société. |
13.7.3 Données, analyse et interprétation
Les parties antérieures de ce chapitre vous ont présenté les principaux éléments à considérer lors de la conception d’une étude de recherche. Bien que ce texte ne cherche pas à vous enseigner l’analyse des données (ce qui nécessite plusieurs autres textes en soi!), cette section vous guide à travers certains des principes fondamentaux de l’analyse des données, afin que vous puissiez déterminer les analyses que vous devez effectuer et utiliser d’autres ressources pour suivre comment effectuer ces analyses avec n’importe quel programme d’analyse de données que vous utilisez.
Dans cette section, nous supposons que vous avez mené votre étude et recueilli vos données. Vous regardez probablement un fichier de données énumérant un grand nombre de chiffres et vous vous demandez que dois-je faire maintenant! Ce chapitre vous aidera à comprendre ce que vous devez savoir pour passer aux étapes suivantes.
13.7.3.1 Données de recherche
L’une des premières choses que vous devez savoir est le type de données dont vous disposez, car cela vous permettra de déterminer quelles analyses vous pouvez effectuer.
Bien qu’il existe de nombreuses définitions, les données qualitatives sont généralement considérées comme des données qui décrivent ou caractérisent ce qu’elles mesurent – il s’agit généralement d’informations descriptives sur les attributs sous forme de mots, que vous ne pouvez pas facilement résumer en chiffres. Si vous menez des études de cas ou des recherches observationnelles, ou utilisez d’autres méthodes ouvertes de collecte de données sur le terrain, vous collecterez souvent des données qualitatives. Il existe de nombreuses façons différentes de présenter et d’analyser les données qualitatives, notamment des approches telles que la Théorie Enracinée, l’Analyse Thématique et l’Analyse de Discours. En revanche, des données quantitatives sont des données qui peuvent être représentées sous forme de chiffres. Mais bien que cela semble simple, toutes les données quantitatives ne sont pas identiques! Dans l’ensemble, il est important de savoir quel type de données que vous avez à disposition, et cela dépend de la manière dont vous avez choisi de mesurer vos variables (voir la définition de l’opérationnalisation ci-dessus).
Si vous prévoyez de réaliser des analyses statistiques sur vos données, il est nécessaire de déterminer auquel des quatre types suivants elles appartiennent.
- Les variables nominales sont des variables qui mesurent à quelle catégorie appartiennent les personnes. Les exemples sont le sexe (féminin, masculin, non binaire, etc.) et la condition dans laquelle se trouve une personne dans une expérience (contrôle, expérimental, etc.).
- Les variables ordinales sont des variables catégorielles qui sont séquencées d’une certaine manière, telles que les notes à l’école (A, B, C, etc.) ou les résultats d’une course (1er, 2e, 3e). En d’autres termes, les catégories « vont » dans un certain ordre. Cependant, ces catégories ordonnées n’ont pas d’intervalles cohérents entre chaque catégorie.
- Les variables d’intervalle sont des variables dans lesquelles les réponses sont quantitativement liées les unes aux autres, avec des intervalles égaux entre elles, mais pas de vrai zéro. Par exemple, le QI est une échelle d’intervalle où le « 0 » n’est pas une véritable absence, tout simplement le score le plus bas sur cette mesure.
- Les variables de ratio sont des variables dans lesquelles les chiffres sont quantitativement liés les uns aux autres et ont un vrai zéro. Cela inclut des variables telles que le poids et la taille.
Une fois que vous savez clairement le type de variable dont vous disposez, vous pouvez déterminer quelles statistiques descriptives et inférentielles vous pouvez effectuer sur ces données.
| Exemples de type de variable commun en robotique
De nombreuses variables ci-dessous peuvent être de différents types – cela dépend de la façon dont vous avez choisi de les mesurer (opérationnaliser) :
|
13.7.3.2 Statistiques descriptives
Les statistiques descriptives sont des énoncés numériques qui résument les données que vous avez recueillies à partir de votre échantillon. Lorsque vous présenterez vos conclusions à votre public, il sera nécessaire de fournir les statistiques descriptives de vos données. Pensez-y : si vous collectez des données auprès de 40 personnes, il ne suffit pas de présenter des chiffres « bruts » dans votre présentation ou rapports Vous devez les résumer d’une manière qui donnera à votre public un aperçu simple de ce à quoi « ressemblent » vos données.
La façon dont vous décrivez vos données dépend du type de données dont vous disposez. Pour les variables catégorielles (nominales ou ordinales), il est courant de signaler le nombre de personnes dans chaque catégorie et/ou le pourcentage de personnes dans chaque catégorie. Par exemple, si vous posez une question aux participants sur leur confiance envers les robots, avec une réponse « oui » ou « non », cela constitue une variable catégorique. Ensuite, vous fournirez un résumé descriptif qui inclura le nombre de personnes (n) ayant répondu oui et le nombre de personnes ayant répondu non. Il est également possible d’indiquer le pourcentage de participants appartenant à chaque catégorie. À titre d’exemple, « sur l’ensemble des participants, 10 personnes (soit 25 %) ont exprimé leur confiance envers les robots, tandis que les 30 autres (soit 75 %) ont déclaré ne pas leur faire confiance ». Il est important de mentionner également le nombre de personnes qui n’ont pas répondu à cette question, le cas échéant.
Si vous disposez de variables numériques (intervalles ou ratios), il est préférable de rapporter la « moyenne » des valeurs de cette variable ainsi que leur dispersion autour de cette valeur centrale, car cela est plus significatif que les n ou les pourcentages pour ce type de variables. Le « milieu » de l’ensemble de données est généralement la moyenne, la médiane ou le mode. La moyenne (M) est calculée en additionnant toutes les valeurs et en divisant par le nombre de valeurs. Le médian est la valeur centrale lorsque toutes les valeurs sont classées de la plus petite à la plus grande, et le mode est la valeur unique la plus courante pour cette variable. Parmi ceux-ci, la moyenne est la plus fréquemment utilisée. Les méthodes les plus fréquentes pour représenter la distribution des données sont la plage et l’écart-type. La plage correspond à la différence entre la valeur minimale et maximale d’une variable. L’écart-type (ET) est une mesure de la variation des valeurs autour de la moyenne – un écart-type plus grand indique que les valeurs sont plus dispersées, tandis qu’un écart-type plus petit indique qu’elles sont moins dispersées. Toutes ces statistiques descriptives peuvent être facilement calculées à l’aide de logiciels statistiques disponibles. Par exemple, si vous mesurez à quelle distance les personnes se tenaient d’un robot (en m), vous pourriez résumer ces données comme suit : « Les participants se tenaient en moyenne à 2,17 m (SD = 0,73) du robot.
13.7.3.3 Statistiques inférentielles
Bien qu’il soit important de présenter les résultats de l’étude pour les participants de votre échantillon (statistiques descriptives), il est généralement souhaitable de faire une déclaration qui dépasse le cadre de votre échantillon, en abordant la signification de vos découvertes pour l’ensemble de la population que vous souhaitez appliquer. Les statistiques inférentielles sont des affirmations numériques qui permettent de tirer des conclusions sur l’ensemble de la population en se basant sur les données de l’échantillon. Bien que l’enseignement des statistiques inférentielles et de la théorie statistique connexe dépasse largement le cadre de ce chapitre, les informations suivantes vous donneront un aperçu rapide de la manière de poser des questions et de demander de l’aide lorsque vous vous lancez dans des analyses.
La première étape consiste à reconnaître vos limites! Une bonne compréhension de la théorie sous-jacente des analyses statistiques, de ce que ces analyses représentent et de ce qu’elles peuvent vous dire (et ne pas vous dire ) est nécessaire pour effectuer correctement des tests statistiques. Il est recommandé de chercher des conseils auprès d’un conseiller statistique, d’un superviseur principal ou de suivre un cours d’introduction aux statistiques (qui sont nombreux en ligne) pour vous perfectionner dans ces domaines. Si vous ne comprenez pas ce que vous faites, vous risquez de mener des analyses inappropriées et/ou de tirer des conclusions inexactes.
Une fois que vous avez une compréhension de base des statistiques inférentielles en général, vous devez décider comment appliquer ces connaissances à votre étude particulière. Le point de départ est vos hypothèses. Au début de l’étude, vous auriez dû formuler des hypothèses particulières – qu’avez-vous prédit exactement? Ces hypothèses serviront de base à vos analyses. Normalement, une étude comprend plusieurs hypothèses différentes, et vous devrez passer par ce processus pour chacune d’entre elles afin de décider quelle analyse est appropriée pour chaque hypothèse. Par exemple, si vous manipulez le type de mouvement que le robot exerce et mesurez la sécurité perçue, vous pouvez également mesurer l’acceptabilité et la distance à laquelle les personnes se tiennent du robot dans la même étude. Ou vous pouvez également manipuler la couleur du robot dans la même étude. Vous auriez des hypothèses séparées pour chacun de ces effets et donc des analyses différentes seraient nécessaires.
Voici les étapes à suivre pour décider et mener des analyses :
- Quelle était votre hypothèse initiale?
- Comment avez-vous opérationnalisé ces variables? Identifiez les VI et VD impliquées dans cette hypothèse particulière (comment les avez-vous exactement mesurées ou manipulées? Y a-t-il des conditions, si oui combien, et sont-elles inter-sujets ou intra-sujets?)
- Quels types de variables sont ces VI et VD? (c’est-à-dire nominale, ordinale, intervalle ou de ratio?)
- Déterminez l’analyse appropriée en fonction de vos variables indépendantes et dépendantes (VI et VD) en utilisant un arbre de décision, tel que celui fourni ci-dessous.
- Vérifiez les hypothèses de cette analyse particulière (par exemple, certains tests nécessitent des données normalement distribuées) et modifiez les analyses si nécessaire (par exemple, pour un test qui ne nécessite pas cette hypothèse).
- Effectuez des analyses et interprétez les résultats.
- Rédigez le résultat en transmettant toutes les informations nécessaires à votre public.
| Exemples de recherche : Sélection et réalisation d’analyses
Considérons l’exemple de Sylax, un projet de recherche en robotique universitaire qui se penche sur l’impact de facteurs tels que le comportement et l’apparence du robot sur l’agentivité perçue par les personnes. Les chercheurs se posent beaucoup de questions sur ces différentes variables, mais dans une étude, ils se concentrent particulièrement sur la comparaison des comportements aléatoires et délibérés.
|
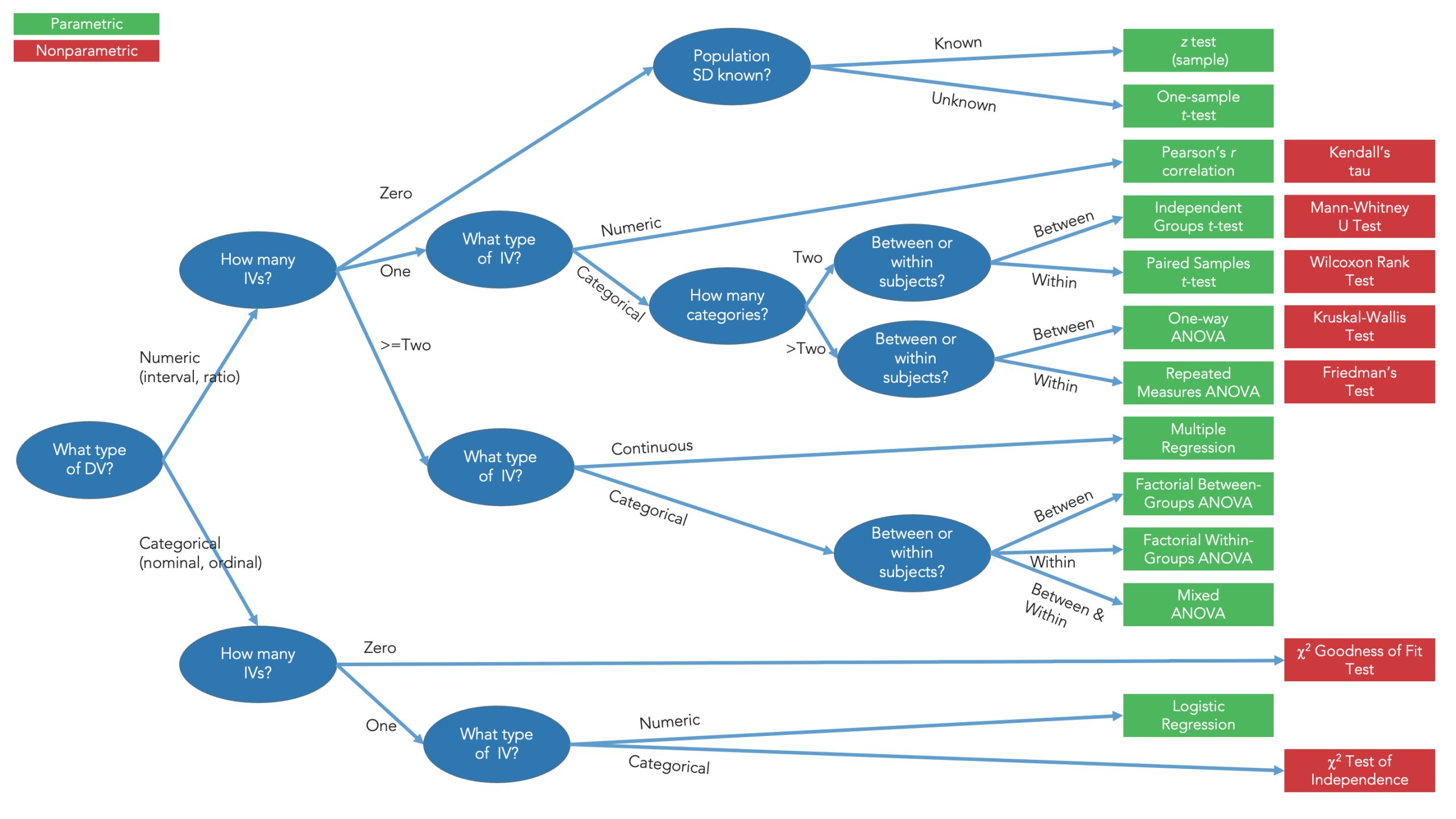
Figure 13-6 : Arbre de décision représentant des analyses statistiques courantes.
13.7.3.4 Présentation des résultats
Lors de la présentation des résultats, il est important de fournir toutes les informations nécessaires pour que le lecteur ou l’audience comprenne quelle analyse a été réalisée, en fournissant les valeurs clés pour qu’ils puissent constater par eux-mêmes les résultats, et de communiquer clairement ce que cela signifie.
Quelques informations clés que vous devez présenter :
- Le nom du test que vous avez effectué.
- Les variables impliquées (et nommer les conditions si cela est pertinent).
- Les résultats de tout test d’hypothèse.
- Les statistiques descriptives clés (par exemple, les moyennes et les écarts-types de chaque groupe).
- Les valeurs clés issues de votre analyse (généralement la valeur de test telle que r, t ou F, le nombre de personnes ou degrés de liberté, la valeur p).
- Informations supplémentaires telles que les intervalles de confiance et les tailles d’effet.
- Si oui ou non le résultat était statistiquement significatif.
- Informations supplémentaires pour faciliter l’interprétation (par exemple, la taille de l’effet, les intervalles de confiance).
- Graphiques ou figures appropriés pour illustrer vos conclusions.
| Exemples de présentations typiques de résultats d’analyses statistiques
Un t-test d’un échantillon apparié été utilisé pour comparer l’agentivité perçue (nombre d’interactions initiées) entre 20 participants exposés à un robot se déplaçant au hasard (M = 4,75, SD = 1,59) et un robot piloté par algorithme (M = 5,55, SD = 2,01). Les vérifications des hypothèses ont confirmé que les données étaient normalement distribuées. Il y avait une différence moyenne de 0,80, IC à 95 % [-1,96, 0,36] entre le nombre d’interactions générées dans les deux conditions, mais cette différence n’était pas significative (t(19) = 1,44, p = 0,166, d = 0,32). Une analyse de corrélation r de Pearson a été réalisée pour examiner la relation entre l’exposition préalable auto-déclarée aux robots et l’attachement à un produit robotique. L’hypothèse de normalité a été confirmée. Il y avait une corrélation modérée, significative et positive entre l’exposition antérieure et les scores d’attachement (r(15) = 0,54, p = 0,026), de sorte que les participants ayant plus de contacts avec des robots avant l’étude avaient tendance à déclarer un attachement plus élevé au robot.
|
13.7.4 Erreurs et pièges courants
Cette section présente les erreurs et les pièges courants que les chercheurs, qu’ils soient novices ou expérimentés, peuvent rencontrer de temps en temps. En sachant quelles sont ces erreurs, vous pourrez les éviter!
L’une des raisons principales pour lesquelles les chercheurs rencontrent des problèmes est qu’ils ne planifient pas les analyses. Il est important de formuler vos hypothèses clés avant de mener votre étude. Quels sont les principaux effets que vous recherchez? Quelles sont les variables clés? Vous pouvez avoir quatre ou cinq hypothèses clés que vous souhaitez tester dans une seule étude. Vos analyses devraient alors être assez simples – vous effectuez les analyses qui testent ces hypothèses! De plus, cette pratique vous protégera contre le « repêchage des données » ou « p-hacking », qui se produit lorsque les chercheurs effectuent de nombreuses analyses différentes sur un seul ensemble de données, mais ne rapportent que les résultats les plus significatifs. Cette pratique est très problématique d’un point de vue statistique, car cela signifie qu’un grand nombre de ces résultats peuvent être des faux positifs. De plus, cette approche reflète une mauvaise compréhension des résultats non significatifs – un résultat qui n’est pas significatif peut toujours être intéressant ou utile! Par exemple, Ne pas trouver de différence significative entre deux conditions peut vous indiquer que vous n’avez pas besoin d’incorporer une capacité supplémentaire pour améliorer la sécurité, ou que les personnes ne peuvent pas différencier les différents visages robotiques.
Lorsque vous obtenez vos données pour la première fois, cela peut être très excitant! Vous avez hâte de voir ce que vous avez découvert, mais il est trop facile de se précipiter dans l’analyse sans comprendre les données. Si vous le faites, vous risquez de vous retrouver avec une pile de résultats qui sont confus!. Et qui sont difficiles à interpréter! Prenez le temps de vous familiariser avec votre ensemble de données : quel est le type de chaque variable? Devriez-vous recoder certaines variables pour les rendre plus utiles? (par exemple, transformer l’âge d’un nombre en une catégorie)? Y a-t-il des données manquantes et cela pose-t-il un problème? Examinez vos données en utilisant des graphiques et des statistiques descriptives. Est-ce que tout semble correct? Y a-t-il des valeurs étranges qui ne devraient pas être là ou des valeurs aberrantes qui pourraient suggérer une panne d’équipement ou une erreur de saisie de données? Vos variables numériques sont-elles normalement distribuées ou violerez-vous certaines hypothèses? Quel est votre plan d’action ci cela se produit?
Une fois que vous avez effectué vos analyses, quelques problèmes courants peuvent survenir? Une erreur que vous voyez fréquemment est que les personnes supposent que la corrélation est égale à la causalité. Par exemple, constater que les personnes ayant déjà été exposées à des robots sont également plus attachées à leur robot compagnon ne prouve pas qu’il y ait une relation causale entre les deux phénomènes. En d’autres termes, cela ne signifie pas que l’augmentation de l’exposition des personnes aux robots entraînera automatiquement une augmentation de leur attachement. Peut-être est-ce une perception positive des robots qui fait augmenter les deux notes? Soyez également prudent lorsque vous interprétez toutes vos conclusions de manière plus générale. Si la taille de votre échantillon est trop petite, vous aurez ce qu’on appelle une puissance faible, ce qui signifie que vous n’avez pas (statistiquement) la capacité de trouver certains effets même s’ils sont vraiment là. Il existe des programmes disponibles (par exemple, G*Power) qui vous permettront de calculer le nombre de personnes dont vous avez besoin dans une étude pour avoir un niveau de puissance particulier. Les échantillons de petite taille sont souvent un défi dans la recherche sur les utilisateurs de robotique. Il est crucial de procéder à une analyse de puissance avant de débuter votre étude afin de déterminer le nombre de participants nécessaire. Finalement, lorsqu’un effet significatif est observé, il est important de prendre en compte également la taille de l’effet (que la plupart des programmes statistiques calculent également pour chaque analyse). Certains effets peuvent être significatifs, mais pas importants! Par exemple, si vous découvrez une différence significative entre la sécurité perçue de deux robots, mais que cette différence n’est que de 0,5 point sur une échelle de 1 à 20, il est peu probable que cela soit une différence importante à la fin de la journée.
L’essentiel à retenir est que vous devez avoir confiance en ce que vous présentez. Êtes-vous sûr que les données reflètent vos conclusions? Y a-t-il des problèmes que le lecteur devrait connaître afin d’interpréter correctement vos résultats? Gardez à l’esprit que d’autres personnes utiliseront votre travail et s’en serviront comme base, il est donc important que ce soit une représentation précise de la réalité!
13.8 Résumé du chapitre
Ce chapitre vous a présenté les bases de la conduite de recherches en Interaction Humain-Robot. Il a été mis en avant l’importance d’une conception minutieuse des projets de recherche, afin de garantir l’obtention d’informations précises et utiles issues des recherches menées. Ce chapitre devrait vous fournir les connaissances et la confiance nécessaires pour concevoir vos propres études dans ce domaine.
13.9 Questions de révision
Question 1 : Vous êtes en train de mener une étude de recherche sur l’effet des visages robotiques sur la perception de l’animéité. Plus précisément, vous vous intéressez à la différence de perception de l’animéité entre les visages d’enfants et les visages d’adultes. Vous avez émis l’hypothèse que les visages d’enfants susciteront plus d’animéité que les visages d’adultes. Ceci est un exemple de :
(a) Théorie
(b) Hypothèse
(c) Condition de contrôle
(d) Compromis pertinence-sensibilité
Question 2 : Vous souhaitez déterminer quelle des trois options de voix pour un robot compagnon suscite la réponse la plus positive de la part du grand public. Vous donnez à un groupe de personnes le même robot avec l’une des trois voix différentes, puis une semaine plus tard, vous leur demandez à quel point ils ont une opinion positive du robot sur une échelle de 1 à 7. Qu’est-ce VI et VD signifient dans cette étude?
(a) VI note positive; VD type de voix.
(b) VI type de robot; VD classement de sécurité.
(c) VI type de voix; VD classement positif.
(d) VI note avant et après; VD type de voix.
Question 3 : Vous évaluez le type d’articulation optimal pour votre conception robotique en examinant toutes les études antérieures réalisées sur l’articulation et en les résumant. Le plan de recherche que vous utilisez est :
(a) Descriptif.
(b) Corrélationnel.
(c) Expérimental.
(d) Examen.
Question 4 : Afin de déterminer les facteurs clés de la conception d’un robot industriel pour une entreprise spécifique, vous diffusez une enquête auprès de tous les employés de l’entreprise. Vous êtes particulièrement intéressé par la relation entre la durée de travail des employés et l’importance qu’ils accordent à certaines caractéristiques de la conception. Le plan de recherche que vous utilisez est :
(a) Descriptif.
(b) Corrélationnel.
(c) Expérimental.
(d) Examen.
Question 5 : Vous testez la réaction des personnes à la nouvelle interface robotique que vous avez conçue. Vous demandez à quelques amis de passer au laboratoire pour vous aider à la tester. De quel type d’échantillonnage s’agit-il ?
(a) Commodité.
(b) Intentionnel.
(c) Probabilité.
(d) Aléatoire.
Question 6 : Vous testez la réaction des personnes à la nouvelle interface robotique que vous avez conçue. Vous leur demandez de faire une tâche à l’aide de l’ancienne interface, puis de faire la même tâche avec la nouvelle interface. Ils font savoir qu’ils ont trouvé qu’il était plus facile d’accomplir la tâche avec la nouvelle interface. Quelle est l’explication pour cette différence?
(a) Effets de l’observateur.
(b) Mortalité.
(c) Effets de la pratique.
(d) Effets historiques.
Question 7 : Vous placez deux caméras vidéo dans un coin de votre laboratoire pour enregistrer les interactions entre vos participants et le robot. Quelles sont les questions éthiques que vous devez prendre en compte?
(a) Consentement éclairé fourni par les participants pour être filmé.
(b) Stockage sécurisé des fichiers vidéo.
(c) Protéger la confidentialité des participants aux vidéos.
(d) Tout ce qui précède.
Question 8 : Vous effectuez un essai pilote en installant un robot dans un environnement de fabrication. Vous mesurez le nombre de fois que les personnes touchent physiquement le robot au cours d’une journée. De quel type de variable s’agit-il?
(a) Ordinal.
(b) Nominal.
(c) Intervalle.
(d) De ratio.
Question 9 : Vous menez un projet de recherche et recueillez certaines données. Vous présentez vos données sous forme de pourcentage de participants qui ont répondu « Tout à fait d’accord » à chaque question. Vous utilisez :
(a) Statistiques inférentielles
(b) Statistiques descriptives
(c) La moyenne et l’écart-type.
(d) Test de signification.
Question 10 : Une enquête menée auprès de la population générale révèle que les personnes qui ont peur des robots sont plus susceptibles de dire qu’elles n’ont pas besoin d’aide robotique à domicile. Les chercheurs en concluent que si la peur des robots diminue chez les personnes, ils seront plus enclins à utiliser des robots pour les aider dans leurs tâches ménagères. Quelle erreur commettent-ils?
(a) Ils font du repêchage des données
(b) Ils ont une faible puissance.
(c) Ils supposent que la corrélation est égale à la causalité.
(d) Ils ont une taille d’effet faible.
RÉFÉRENCES
Theory of mind – Leslie, A. M. (1987). Pretense and representation: The origins of « theory of mind. » Psychological Review, 94(4), 412. https://doi.org/10.1037/0033-295X.94.4.412
Attachment Theory – Bretherton, I. (1985). Attachment Theory: Retrospect and Prospect. Monographs of the Society for Research in Child Development, 50(1/2), 3-35. doi:10.2307/3333824 https://doi.org/10.2307/3333824
Behavioural Decision Theory – Slovic, P., Fischhoff, B., & Lichtenstein, S. (1984). Behavioral decision theory perspectives on risk and safety. Acta psychologica, 56(1-3), 183-203. https://doi.org/10.1016/0001-6918(84)90018-0
The jamovi project (2021). jamovi (Version 1.6) [Computer Software]. Retrieved from https://www.jamovi.org
Liste des figures
Figure 13-2 : Approches qui peuvent vous aider à décider comment opérationnaliser les variables.
Figure 13-3 : Une catégorisation des différents types de modèles de recherche.
Figure 13-5 : Avantages et inconvénients des conceptions de recherche intra-sujets et inter-sujets.
Figure 13-6 : Arbre de décision représentant des analyses statistiques courantes.
