
5 Manipulations avancées dans GEE
Apprentissage machine sous GEE
L’apprentissage machine (ML) est une technique puissante d’analyse des données d’observation de la Terre. Google Earth Engine dispose de capacités intégrées permettant aux utilisateurs de créer et d’utiliser des modèles d’apprentissage automatique pour des scénarios courants grâce à des API faciles à utiliser.
Les trois principales tâches de l’apprentissage automatique sont la classification supervisée, la classification non supervisée et la régression.
Classification supervisée
Dans GEE, le package ee.Classifier nous aide à effectuer une classification supervisée par des algorithmes d’apprentissage machine traditionnels.
Vous pouvez voir la liste des classificateurs disponibles dans l’onglet « Docs » du panneau de gauche de la fenêtre de code de GEE (Figure 85).
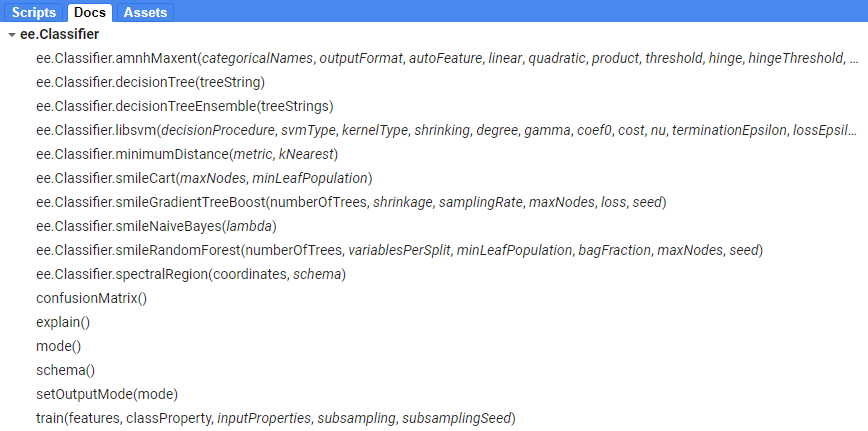
Le flux de travail général pour la classification est le suivant :
- Recueillir les données d’apprentissage en tant que FeatureCollection. Assemblez les caractéristiques avec une propriété qui stocke l’étiquette de classe connue et des propriétés stockant des valeurs numériques pour les prédicteurs. Les étiquettes de classe (‘Class‘) doivent être des entiers consécutifs commençant par 0. Les données d’entraînement/validation peuvent provenir de diverses sources. Pour collecter des données d’entraînement de manière interactive dans Earth Engine, vous pouvez utiliser les outils de dessin géométrique. Vous pouvez également importer des données d’entraînement prédéfinies à partir de « Assets »;
- Instanciez un classificateur à partir de ee.Classifier et définissez ses paramètres;
- Entraînez le classificateur en utilisant les données d’entraînement;
- Classifier une image;
- Estimer l’erreur de classification avec des données de validation indépendantes.
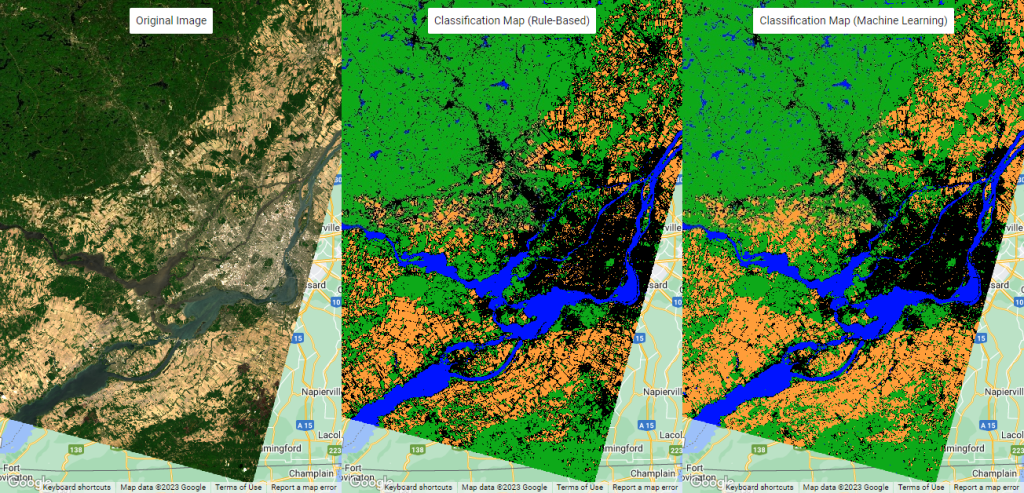
Nous allons voir un exemple montrant comment effectuer toutes les étapes mentionnées ci-dessus. Considérez la classification basée sur des règles dans la section « Opérations booléennes, relationnelles et conditionnelles » au chapitre 3. Cette fois, nous voulons effectuer une classification en utilisant des algorithmes ML. Ainsi, dans la version de l’exemple basée sur des règles, nous avons utilisé quatre couches NDVI, NDWI, SWIR et DEM pour classer notre scène d’image dans les classes Végétation, Urbain, Sols nus et Eau. Nous utilisons ici les mêmes couches comme entrées du classificateur ML pour l’entraînement.
var image = ee.Image(‘LANDSAT/LC08/C01/T1_SR/LC08_015028_20210529’);
Map.addLayer(image, {bands :[‘B4’,‘B3’,‘B2’],min: 108, max:1848}, ‘L8 Image’);
var image = image.select([‘B7’, ‘B5’, ‘B4’, ‘B3’,’ B2’],[‘swir’, ‘nir’, ‘red’, ‘green’, ‘blue’]);
var ndvi = image.normalizedDifference([‘nir’,‘red’]).rename(‘NDVI’);
var ndwi = image.normalizedDifference([‘blue’,‘swir’]).rename(‘NDWI’);
var swir = image.select([‘swir’]).rename(‘SWIR’);
var dem = ee.Image(‘USGS/SRTMGL1_003’).rename(‘DEM’).clip(image.geometry());
La première chose à faire est de fournir des données d’entraînement, et ici nous utilisons les outils de dessin géométrique pour préparer les données d’entraînement comme un mélange de points et de polygones. L’utilisation de « + new layer » crée un nouveau calque qui nous permettra d’y ajouter des géométries comme ensemble d’entraînement d’une classe. Ensuite, cliquez sur l’engrenage ![]() pour modifier le réglage de la géométrie, ce qui ouvrira une fenêtre vous permettant de créer des attributs associés aux géométries dessinnées.
pour modifier le réglage de la géométrie, ce qui ouvrira une fenêtre vous permettant de créer des attributs associés aux géométries dessinnées.
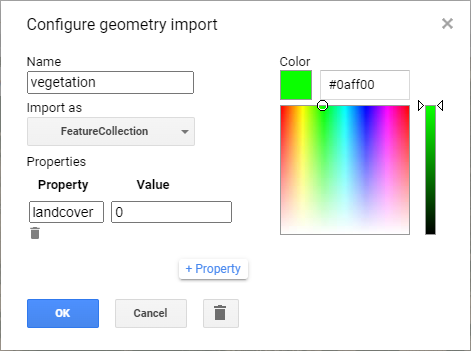
Définissez le nom de votre classe spécifique (par exemple, végétation) et changez le type de géométrie en FeatureCollection (dans la liste déroulante « Import as« ). Ensuite, cliquez sur + pour créer une propriété qui sera commune pour vos classes et vos entités. Changez le nom de la propriété en « landcover » dans la case « Properties » (parce qu’ici nous voulons classer les classes d’occupation du sol) et définissez un ID d’étiquette pour la classe dans la case « Value » (par exemple, l’étiquette pour la classe de végétation est ici 0) (Figure 86).
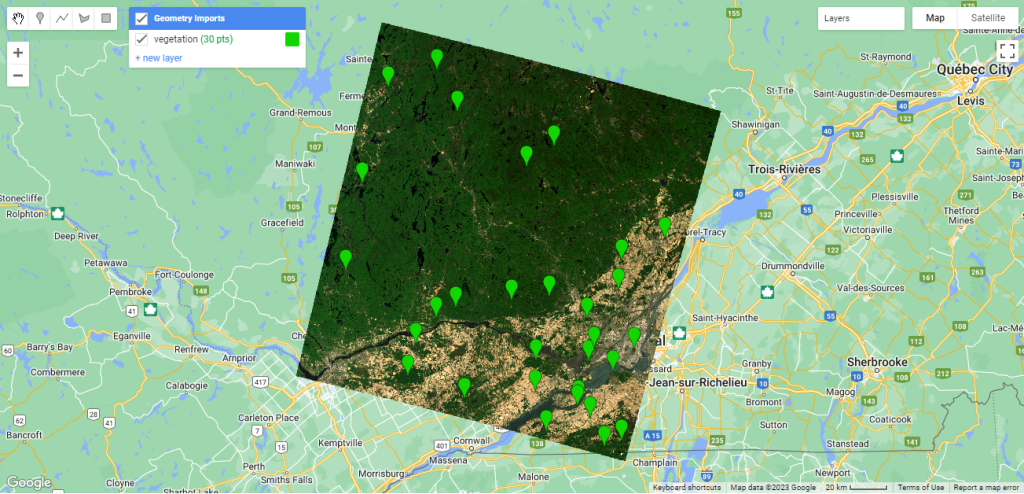
Ensuite, vous pouvez sélectionner stratégiquement des points ou se trouve de la végétation sur la carte en fonction de l’image que vous voulez classer (Figure 87). Essayez de répartir vos points ou polygones dans différentes parties de l’image présentant des conditions différentes.
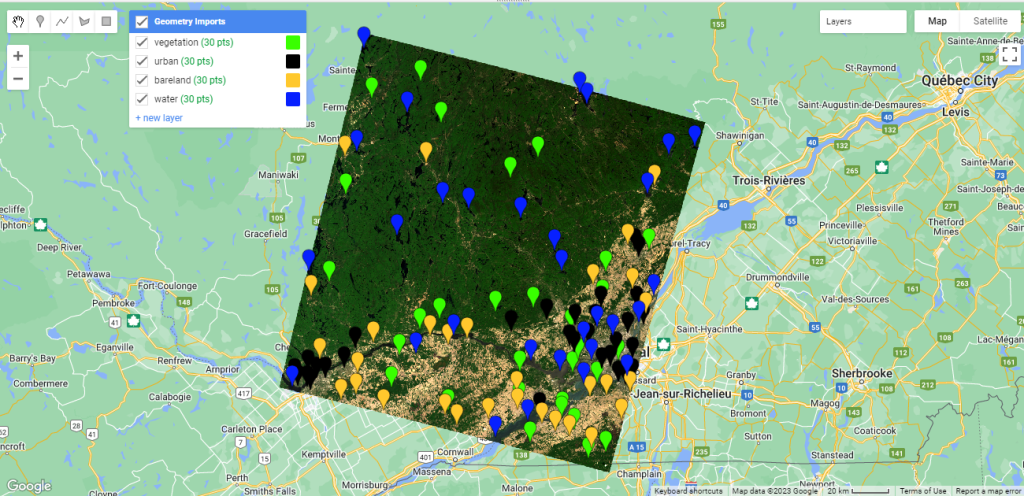
Il faut ensuite répéter l’exercice pour les classes « urbain », « sols nus » et « eau » (Figure 88). N’oubliez pas de spécifier une valeur d’étiquette et une couleur uniques pour chaque classe.
Astuce
Pour effectuer la classification, il faut ensuite faire appel au code suivant.
// Selectionner les bandes à utiliser en entrée pour l’algorithme de ML.
var new_image = ee.Image.cat([ndvi, ndwi, swir, dem]);
// Fusionner les géométries des classes d’occupation du sol en une seule FeatureCollection.
var points = vegetation.merge(urban).merge(bareland).merge(water);
// Extraire les caractéristiques spectrales de chaque bande en entrée en fonction des géométries d’entraînement fournies.
var training = new_image.sampleRegions({collection: points, properties: [‘landcover’], scale: 30});
// Entraînement d’un modèle de forêt d’arbres aléatoires (Random Forest) avec 10 arbres.SMILE réfère à « Statistical Machine Intelligence and Learning Engine » une librairie JAVA utilisée par GEE.
var classifier = ee.Classifier.smileRandomForest(10).train({features: training, classProperty: ‘landcover’, inputProperties: [‘NDVI’, ‘NDWI’, ‘SWIR’, ‘DEM’]});
// Imprimer dans la console des informations sur le classificateur.
print(‘Classifier Information’, classifier.explain());
// Classifier une image disposant des mêmes bandes que celles fournies en entrée au classificateur.
var classified = new_image.classify(classifier);
Map.addLayer(classified, {min: 0, max: 3, palette: [‘#0da919’, ‘#000000’, ‘#ff9d39’, ‘#0014ff’]}, ‘Classification Map (Machine Learning)’)
L’on peut alors comparer les résultats obtenus avec l’approche par « règles » présentée au chapitre 3 et ceux fournis par notre forêt d'arbres aléatoires (Figure 89).
Estimation de l’exactitude des résultats
Une fois l’apprentissage du classificateur effectué, nous pouvons évaluer son exactitude sur la prédiction de l’occupation du sol. À cette fin, nous devons utiliser une matrice de confusion. Il y a une question importante que vous devez considérer avant d’évaluer votre classificateur. Nous devons évaluer l’exactitude de la classification en utilisant des données que l’algorithme n’a pas encore vues. Ces données sont appelées l’ensemble de validation/test. Vous pouvez, afin de préalablement obtenir cette partition des données, utiliser la méthode randomColumn() sur vos échantillons d’entraînement.
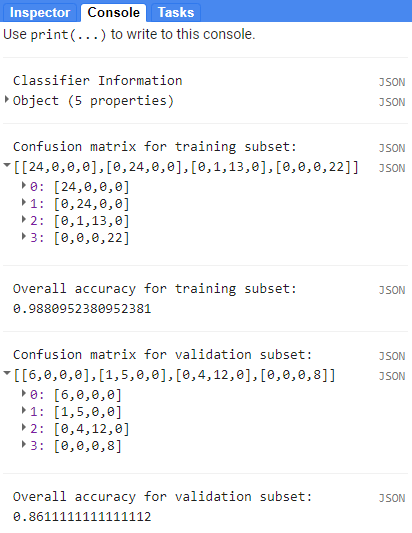
Voici à quoi ressemble le code à utiliser pour générer la matrice de confusion (Figure 90) sur le résultat random forest précédent.
var image = ee.Image(‘LANDSAT/LC08/C01/T1_SR/LC08_015028_20210529’);
Map.addLayer(image, {bands :[‘B4’,‘B3’,‘B2’],min: 108, max:1848}, ‘L8 Image’);
var image = image.select([‘B7’, ‘B5’, ‘B4’, ‘B3’,’ B2’],[‘swir’, ‘nir’, ‘red’, ‘green’, ‘blue’]);
var ndvi = image.normalizedDifference([‘nir’,‘red’]).rename(‘NDVI’);
var ndwi = image.normalizedDifference([‘blue’,‘swir’]).rename(‘NDWI’);
var swir = image.select([‘swir’]).rename(‘SWIR’);
var dem = ee.Image(‘USGS/SRTMGL1_003’).rename(‘DEM’).clip(image.geometry());
// Selectionner les bandes à utiliser en entrée pour l’algorithme de ML.
var new_image = ee.Image.cat([ndvi, ndwi, swir, dem]);
// Fusionner les géométries des classes d’occupation du sol en une seule FeatureCollection.ureCollection.
var points = vegetation.merge(urban).merge(bareland).merge(water);
// Ajoutez une colonne « Random » et divisez les échantillons de formation en ensembles d’entraînement et de validation.
var points = points.randomColumn();
var split = 0.7; // Séparation 70% entraînement, 30% validation.
var training_samples = points.filter(ee.Filter.lt(‘random’, split));
var validation_samples = points.filter(ee.Filter.gte(‘random’, split));
// Extraire les caractéristiques spectrales de chaque bande en entrée en fonction des géométries d’entraînement fournies.
var training = new_image.sampleRegions({collection: training_samples, properties: [‘landcover’], scale: 30});
// Entraînement d’un modèle de forêt d’arbres aléatoires (Random Forest) avec 10 arbres.SMILE réfère à « Statistical Machine Intelligence and Learning Engine » une librairie JAVA utilisée par GEE.
var classifier = ee.Classifier.smileRandomForest(10).train({features: training, classProperty: ‘landcover’, inputProperties: [‘NDVI’, ‘NDWI’, ‘SWIR’, ‘DEM’]});
// Imprimer dans la console des informations sur le classificateur.
print(‘Classifier Information’, classifier.explain());
// Obtenez une matrice de confusion représentant la précision du sous-ensemble d’entraînement.
var trainAccuracy = classifier.confusionMatrix();
print(‘Confusion matrix for training subset: ‘, trainAccuracy);
print(‘Overall accuracy for training subset: ‘, trainAccuracy.accuracy());
print(‘Producers accuracy for training subset: ‘, trainAccuracy.producersAccuracy());
print(‘Consumers accuracy for training subset: ‘, trainAccuracy.consumersAccuracy());
print(‘Kappa for training subset: ‘, trainAccuracy.kappa());
// Classifier l’image avec les mêmes bandes que celles utilisées pour l’entraînement du classificateur.
var classified = new_image.classify(classifier);
Map.addLayer(classified, {min: 0, max: 3, palette: [‘#0da919’, ‘#000000’, ‘#ff9d39’, ‘#0014ff’]}, ‘Classification Map (Machine Learning)’)
// Générer des données de validation avec les échantillons et la nouvelle_image. Il suffit de superposer les échantillons de validation avec la nouvelle image.
var validation = new_image.sampleRegions({collection: validation_samples, properties: [‘landcover’],scale: 30});
// Prédire sur le sous-ensemble de validation avec le classificateur entraîné.
var test = validation.classify(classifier);
// Obtenez une matrice de confusion représentant la précision du sous-ensemble de validation des données de l’échantillon. Chaque échantillon dans le « test » a deux propriétés : « landcover » représente la vraie étiquette de classe de l’échantillon, et « classification » représente l’étiquette de classe prédite par le classificateur.
var testAccuracy = test.errorMatrix(‘landcover’, ‘classification’);
print(‘Confusion matrix for validation subset: ‘, testAccuracy);
print(‘Overall accuracy for validation subset: ‘, testAccuracy.accuracy());
print(‘Producers accuracy for validation subset: ‘, testConfusionMatrix.producersAccuracy());
print(‘Consumers accuracy for validation subset: ‘, testConfusionMatrix.consumersAccuracy());
print(‘Kappa for validation subset: ‘, testConfusionMatrix.kappa());
Ajout d’une légende
Une légende est un guide simple composé de symboles/couleurs avec leurs descriptions correspondantes qui montrent ce que représente un symbole/couleur. Cela nous permettra de mieux comprendre la carte (Figure 91). Ici, nous allons créer une légende pour la carte de classification produite par l’algorithme Random Forest.
// Ajuster la position de la légende
var legend = ui.Panel({ style: {position: ‘bottom-left’, padding: ‘8px 15px’}});
// Ajuster le titre de la légende
var legendTitle = ui.Label({value: ‘Landcover Classes’, style: {fontWeight: ‘bold’, fontSize: ‘18px’, margin: ‘0 0 4px 0’, padding: ‘0’}});
// Joindre la légende et son titre dans une seule entité
legend.add(legendTitle);
var makeRow = function(color, name) {var colorBox = ui.Label({style: {backgroundColor: color, padding: ‘8px’, margin: ‘0 0 4px 0’}});
var description = ui.Label({value: name, style: {margin: ‘0 0 4px 6px’}});
return ui.Panel({widgets: [colorBox, description], layout: ui.Panel.Layout.Flow(‘horizontal’)});};
// Créer les lignes de la légende en passant la couleurs désirée et la classe correspondante à la fonction « makeRow » et en les ajoutant à la légende.
legend.add(makeRow(‘#0da919’, ‘Vegetation’));
legend.add(makeRow(‘#000000’, ‘Urban’));
legend.add(makeRow(‘#ff9d39’, ‘Bare land’));
legend.add(makeRow(‘#0014ff’, ‘Water’));
// Ajouter la légende à la carte
Map.add(legend);

Classification non-supervisée
Dans GEE, le paquetage ee.Clusterer nous aide à effectuer une classification non supervisée (ou clustering). Vous pouvez voir la liste des classificateurs non supervisés dans l’onglet « Docs » du panneau gauche de l’interface de code de GEE (Figure 92).
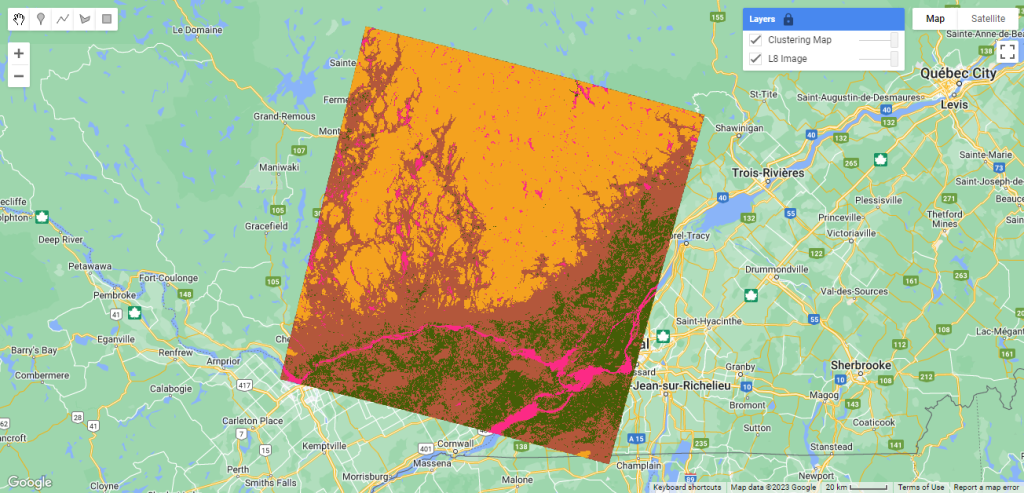
Nous utiliserons la même image et les mêmes bandes que celles utilisées dans la classification supervisée pour démontrer un exemple de classification non supervisée (Figure 93).
var image = ee.Image(‘LANDSAT/LC08/C01/T1_SR/LC08_015028_20210529’);
Map.addLayer(image, {bands :[‘B4’,‘B3’,‘B2’],min: 108, max:1848}, ‘L8 Image’);
var image = image.select([‘B7’, ‘B5’, ‘B4’, ‘B3’,’ B2’],[‘swir’, ‘nir’, ‘red’, ‘green’, ‘blue’]);
var ndvi = image.normalizedDifference([‘nir’,‘red’]).rename(‘NDVI’);
var ndwi = image.normalizedDifference([‘blue’,‘swir’]).rename(‘NDWI’);
var swir = image.select([‘swir’]).rename(‘SWIR’);
var dem = ee.Image(‘USGS/SRTMGL1_003’).rename(‘DEM’).clip(image.geometry());
// Selectionner les bandes à utiliser en entrée pour l’algorithme de ML.
var new_image = ee.Image.cat([ndvi, ndwi, swir, dem]);
// Définir une région d’intérêt, ici c’est l’image en entier.
var roi = image.geometry();
// Entrainer l’algorithme sur l’entièreté de l’image est un processus très lourd. On indique donc à l’algorithme de ne considérer que 5000 pixels pour son entraînement.
var training = new_image.sample({region: roi, scale: 30, numPixels: 5000});
// Definir la méthode de « clustering » – KMeans – et le nombre de classes (4) à identifier.
var clusterer = ee.Clusterer.wekaKMeans(4).train(training);
// Segmenter l’image en N classes grâce au « clusterer » entraîné.
var clustering_map = new_image.cluster(clusterer);
// Afficher la carte segmentée avec un code de couleurs aléatoire
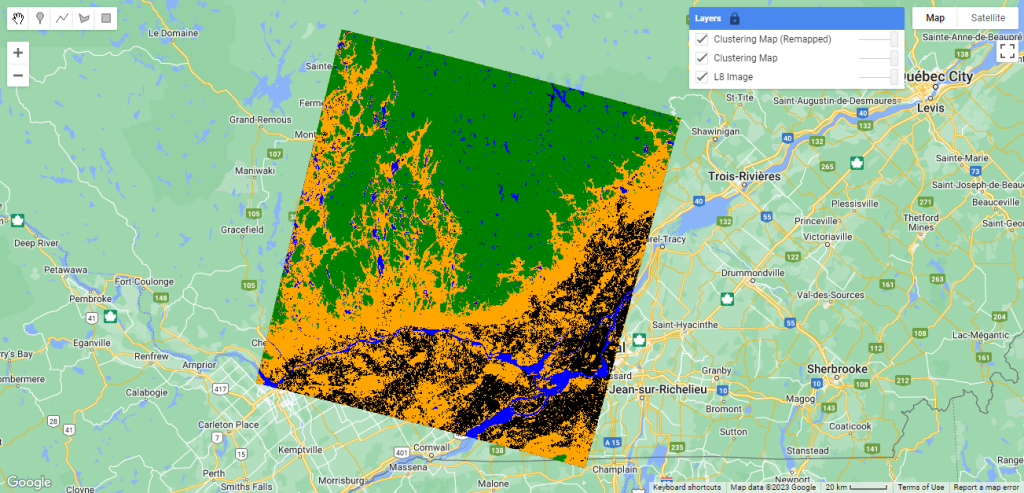
Map.addLayer(clustering_map.randomVisualizer(), {}, ‘Clustering Map’);
Astuce
Vous pouvez utiliser la fonction remap pour changer la valeur numérique associée aux classes (Figure 94).
// Remap 0 vers 3, 1 vers 1, 2 vers 0, 3 vers 2
clustering_map = clustering_map.remap([0, 1, 2, 3], [3, 1, 0, 2]);
Map.addLayer(clustering_map, {min: 0, max: 3, palette: [‘green’, ‘black’, ‘orange’, ‘blue’]}, ‘Clustering Map’);
Mode d'apprentissage par lequel un agent évalue et améliore ses performances et son efficacité sans que son programme soit modifié, en acquérant de nouvelles connaissances et aptitudes à partir de données et/ou en réorganisant celles qu'il possède déjà. (OQLF, 2020)
Une API (application programming interface ou « interface de programmation d’application ») est une interface logicielle qui permet de « connecter » un logiciel ou un service à un autre logiciel ou service afin d’échanger des données et des fonctionnalités. (CNIL, 2023)
Méthode déterministe destinée à obtenir des classes de pixels ou des catégories thématiques par un traitement interactif des données en fonction de la réalité de terrain. (FranceTerme, 2020)
Méthode probabiliste d'analyse d'un fichier de données, destinée à créer des classes de pixels, par des traitements mathématiques. (FranceTerme, 2000)
Mesure télédétectée par satellite de la « verdure » du couvert végétal. (OMS, 2011)
L'indice NDWI est utilisé pour surveiller les changements liés à la teneur en eau des masses d'eau. Comme les masses d'eau absorbent fortement la lumière dans le spectre électromagnétique visible à infrarouge, le NDWI utilise les bandes verte et proche infrarouge pour mettre en évidence les masses d'eau. Il est sensible aux terrains bâtis et peut entraîner une surestimation des masses d'eau. (Wikipédia, 2021)
En apprentissage automatique, les forêts d'arbres décisionnels (ou forêts aléatoires de l'anglais random forest classifier) forment une méthode d'apprentissage ensembliste. Ils ont été premièrement proposées par Ho en 1995 et ont été formellement proposées en 2001 par Leo Breiman et Adele Cutler. Cet algorithme combine les concepts de sous-espaces aléatoires et de bagging. L'algorithme des forêts d'arbres décisionnels effectue un apprentissage sur de multiples arbres de décision entraînés sur des sous-ensembles de données légèrement différents. (Wikipédia, 2022)
En apprentissage automatique supervisé, la matrice de confusion est une matrice qui mesure la qualité d'un système de classification. Chaque ligne correspond à une classe réelle, chaque colonne correspond à une classe estimée. La cellule ligne L, colonne C contient le nombre d'éléments de la classe réelle L qui ont été estimés comme appartenant à la classe C1. Attention il y a parfois interversion des axes de la matrice en fonction des auteurs.
Un des intérêts de la matrice de confusion est qu'elle montre rapidement si un système de classification parvient à classifier correctement. (Wikipédia, 2022)
